Twitter Data in R
Collection | Cleaning | Analysis
Resul Umit
March 2022
Who am I?
Resul Umit
post-doctoral researcher at the University of Oslo
interested in representation, elections, and parliaments
- a recent publication: Parliamentary communication allowances do not increase electoral turnout or incumbents’ vote share
Who am I?
Resul Umit
post-doctoral researcher at the University of Oslo
interested in representation, elections, and parliaments
- a recent publication: Parliamentary communication allowances do not increase electoral turnout or incumbents’ vote share
working with Twitter data
a publication based on Twitter data: The voices of Eurosceptic members of parliament (MPs) echo disproportionately louder on Twitter
- 400,000+ tweets from 1,000+ MPs
- automated classification, using a bag-of-words approach
- manual validation
an app based on Twitter data: LikeWise — a Shiny app that facilitates searching the tweets a user liked
Who am I?
Resul Umit
post-doctoral researcher at the University of Oslo
interested in representation, elections, and parliaments
- a recent publication: Parliamentary communication allowances do not increase electoral turnout or incumbents’ vote share
working with Twitter data
a publication based on Twitter data: The voices of Eurosceptic members of parliament (MPs) echo disproportionately louder on Twitter
- 400,000+ tweets from 1,000+ MPs
- automated classification, using a bag-of-words approach
- manual validation
an app based on Twitter data: LikeWise — a Shiny app that facilitates searching the tweets a user liked
- more information available at resulumit.com
The Workshop — Overview
Two days, on how to collect, process, and analyse data from Twitter
- ~200 slides, 75+ exercises
- support for applications to Twitter, developing real projects
The Workshop — Overview
Two days, on how to collect, process, and analyse data from Twitter
- ~200 slides, 75+ exercises
- support for applications to Twitter, developing real projects
Designed for researchers with basic knowledge of R programming language
- does not cover programming with R
- e.g., writing functions
- e.g., writing functions
- existing ability to work with data in R will be very helpful
- especially while processing and analysing data
- but not absolutely necessary — this ability can be developed during and after the workshop as well
- does not cover programming with R
The Workshop — Motivation
Twitter provides attractive opportunities for academic research
- a simple search for "twitter data" returns 74,000+ results on Google Scholar
- at the beginning of March 2022
- a simple search for "twitter data" returns 74,000+ results on Google Scholar
The Workshop — Motivation
Twitter provides attractive opportunities for academic research
- a simple search for "twitter data" returns 74,000+ results on Google Scholar
- at the beginning of March 2022
- a simple search for "twitter data" returns 74,000+ results on Google Scholar
Research based on Twitter data requires a set of skills
- typically, these skills are not part of academic training
The Workshop — Motivation — Opportunities
Popularity of the network
- about 220 million users, more than three quarters are daily active
- your subjects are likely Twitter users
- e.g., for me, members of parliament
The Workshop — Motivation — Opportunities
Popularity of the network
- about 220 million users, more than three quarters are daily active*
- your subjects are likely Twitter users
- e.g., for me, members of parliament
Richness of the data
- about 500 million tweets per day*
- with up to 90 variables for each tweet
* These statistics are compiled at the end of 2021, by BusinessOfApps.
The Workshop — Motivation — Opportunities
Popularity of the network
- about 220 million users, more than three quarters are daily active
- your subjects are likely Twitter users
- e.g., for me, members of parliament
Richness of the data
- about 500 million tweets per day
- with up to 90 variables for each tweet
Accessibility of the data
- most Twitter data are public
- i.e., relatively few private profiles
- i.e., relatively few private profiles
- APIs (application programming interfaces) enable programmatic access to Twitter
- e.g., downloading tweets with R, as opposed to viewing tweets as visualised via browsers
- most Twitter data are public
The Workshop — Motivation — Challenges
Research based on Twitter data requires certain skills
- e.g., availability of API is meaningless for researchers who cannot code yet
- processing and analysing data are no less challenging without programming skills
The Workshop — Motivation — Challenges
Research based on Twitter data requires certain skills
- e.g., availability of API is meaningless for researchers who cannot code yet
- processing and analysing data are no less challenging without programming skills
The required skills are often uncovered in the academic training of social scientists
- e.g., methodology courses
- but help is available elsewhere, including
- collaboration with researchers with the skills
- at the cost of sacrificing some control over your research and research agenda
- at the cost of sacrificing some control over your research and research agenda
- acquiring the skills through individual effort
- e.g., workshops such as this one
- collaboration with researchers with the skills
The Workshop — Motivation — Aims
To provide you with an understanding of what is possible
- we will cover a large breath of issues, not all of it is for long-term memory
- hence the slides are designed for self study as well
- hence the slides are designed for self study as well
- awareness of what is possible,
Google, and perseverance are all you need
- we will cover a large breath of issues, not all of it is for long-term memory
The Workshop — Motivation — Aims
To provide you with an understanding of what is possible
- we will cover a large breath of issues, not all of it is for long-term memory
- hence the slides are designed for self study as well
- hence the slides are designed for self study as well
- awareness of what is possible,
Google, and perseverance are all you need
- we will cover a large breath of issues, not all of it is for long-term memory
To start you with acquiring and practicing the skills needed
- practice with ready-written code
- start working on a real project
The Workshop — Contents
Part 1. Preliminary Considerations
- e.g., considering Twitter for research
Part 2. Getting the Tools Ready
- e.g., downloading course material
- e.g., acquiring a user's tweets
- e.g., creating a tidy dataset of tweets
- e.g., conducting network analysis
- e.g., conducting sentiment analysis
The Workshop — Organisation
I will go through a number of slides...
- introducing things
- demonstrating how-to do things
... and then pause, for you to use/do those things
- e.g., prepare your computer for the workshop, and/or
- complete a number of exercises
We are here to help
- ask me, other participants
- consult Google, slides, answer scripts
- type, rather than copy and paste, the code you will find on the slides or the script
The Workshop — Organisation — Slides
Slides with this background colour indicate that your action is required, for
setting the workshop up
- e.g., installing R
completing the exercises
- e.g., downloading tweets
- there are 75+ exercises
- these slides have countdown timers
- as a guide, not to be followed strictly
03:00
The Workshop — Organisation — Slides
Codes and texts that go in R console or scripts appear as such — in a different font, on gray background
- long codes and texts will have their own line(s)
# read in the tweets datasetdf <- read_rds("tweets.rds") %>%# split the variable text, create a new variable called da_tweets unnest_tokens(output = da_tweets, input = text, token = "tweets") %>%# remove rows that match any of the stop words as stored in the stop_words dataset anti_join(stop_words, by = c("da_tweets" = "word"))The Workshop — Organisation — Slides
Codes and texts that go in R console or scripts appear as such — in a different font, on gray background
- long codes and texts will have their own line(s)
Results that come out as output appear as such — in the same font, on green background
- except very obvious results, such as graphs
The Workshop — Organisation — Slides
Codes and texts that go in R console or scripts appear as such — in a different font, on gray background
- long codes and texts will have their own line(s)
Results that come out as output appear as such — in the same font, on green background
- except very obvious results, such as graphs
Specific sections are highlighted yellow as such for emphasis
- these could be for anything — codes and texts in input, results in output, and/or texts on slides
The Workshop — Organisation — Slides
Codes and texts that go in R console or scripts appear as such — in a different font, on gray background
- long codes and texts will have their own line(s)
Results that come out as output appear as such — in the same font, on green background
- except very obvious results, such as graphs
Specific sections are highlighted yellow as such for emphasis
- these could be for anything — codes and texts in input, results in output, and/or texts on slides
The slides are designed for self-study as much as for the workshop
- accessible, in substance and form, to go through on your own
Considerations — Research Questions & Hypotheses
Ideally, we have one or more research questions, hypotheses
- developed prior to data collection, analysis
- based on, e.g., theory, claims, observations
- based on, e.g., theory, claims, observations
- perhaps, even pre-registered
- e.g., at OSF Registries
- developed prior to data collection, analysis
Considerations — Research Questions & Hypotheses
Ideally, we have one or more research questions, hypotheses
- developed prior to data collection, analysis
- based on, e.g., theory, claims, observations
- based on, e.g., theory, claims, observations
- perhaps, even pre-registered
- e.g., at OSF Registries
- developed prior to data collection, analysis
Not all questions can be answered with Twitter data
- see relevant literature for what works, what does not
- e.g., for political science, the review by (Jungherr, 2016)
- for public health, the review by (Sinnenberg, Buttenheim, Padrez, Mancheno, Ungar, and Merchant, 2017)
- see relevant literature for what works, what does not
Considerations — Potential Biases
There are at least two potential sources of bias in Twitter data
sampling
- Twitter users are not representative of the people out there
- see, for example, (Mellon and Prosser, 2017)
- see, for example, (Mellon and Prosser, 2017)
- Tweeting behaviour has a strategic component
- see, for example, (Umit, 2017)
- Twitter users are not representative of the people out there
Considerations — Potential Biases
There are at least two potential sources of bias in Twitter data
sampling
- Twitter users are not representative of the people out there
- see, for example, (Mellon and Prosser, 2017)
- see, for example, (Mellon and Prosser, 2017)
- Tweeting behaviour has a strategic component
- see, for example, (Umit, 2017)
- Twitter users are not representative of the people out there
mediation
- the behaviour on Twitter is mediated through written and unwritten rules
- e.g., there is a button to like, but no dislike
- might systematically bias the replies towards negative
- might systematically bias the replies towards negative
- e.g., the common use of the like function as a bookmark
- what would a study of Twitter likes be measuring?
- e.g., there is a button to like, but no dislike
- the behaviour on Twitter is mediated through written and unwritten rules
Considerations — Constraints over Data Access
Twitter has restrictions on data access
- how much data is available to download
- how quickly, how frequently, how far dating back etc.
Considerations — Constraints over Data Access
Twitter has restrictions on data access
- how much data is available to download
- how quickly, how frequently, how far dating back etc.
These restrictions vary across API types
- e.g., Standard v1.1 is the most restrictive APIs
- other first generation APIs are the Premium v1.1 and Enterprise: Gnip 2.0 APIs — both with paid subscriptions
- there are also the second generation APIs, including the newly announced Academic Research access
- e.g., Standard v1.1 is the most restrictive APIs
Considerations — Constraints over Data Access
Twitter has restrictions on data access
- how much data is available to download
- how quickly, how frequently, how far dating back etc.
These restrictions vary across API types
- e.g., Standard v1.1 is the most restrictive APIs
- other first generation APIs are the Premium v1.1 and Enterprise: Gnip 2.0 APIs — both with paid subscriptions
- there are also the second generation APIs, including the newly announced Academic Research access
- e.g., Standard v1.1 is the most restrictive APIs
These restrictions also vary within APIs types, across different operations
- e.g., collecting tweets in real time vs. collecting historical tweets
- but also, collecting historical tweets from a specific user vs. tweets from any user
- e.g., collecting tweets in real time vs. collecting historical tweets
Considerations — Constraints over Data Redistribution
Twitter restricts content redistribution
- e.g., only the tweet and/or user IDs can be made publicly available in datasets over 50,000 observations
- e.g., not the tweets themselves
- and no more than 1.5M IDs
- with some exceptions for academic research
- with some exceptions for academic research
- see Twitter Developer terms for further details
- e.g., only the tweet and/or user IDs can be made publicly available in datasets over 50,000 observations
Considerations — Constraints over Data Redistribution
Twitter restricts content redistribution
- e.g., only the tweet and/or user IDs can be made publicly available in datasets over 50,000 observations
- e.g., not the tweets themselves
- and no more than 1.5M IDs
- with some exceptions for academic research
- with some exceptions for academic research
- see Twitter Developer terms for further details
- e.g., only the tweet and/or user IDs can be made publicly available in datasets over 50,000 observations
Reproducibility of research based on Twitter data is limited in practice
- i.e., reproducibility after publication, by others
- technically, they can retrieve the same tweets with IDs
- demanding for reproducers
- may even be impossible
- e.g., some tweets, or whole accounts, might be deleted before replication attempts
Considerations — Changes in the Twitter APIs
Twitter is currently switching to a new generation of APIs
- replacing APIs v1 with v2
- each with various types of APIs
- each with various types of APIs
- the switch is not complete, outcome is not clear
- see the early access options
- replacing APIs v1 with v2
Considerations — Changes in the Twitter APIs
Twitter is currently switching to a new generation of APIs
- replacing APIs v1 with v2
- each with various types of APIs
- each with various types of APIs
- the switch is not complete, outcome is not clear
- see the early access options
- replacing APIs v1 with v2
Twitter might change the rules of the APIs game at any anytime, again
- making the existing restrictions more or less strict
- e.g., while you are in the middle of data collection
- e.g., while you are in the middle of data collection
- breaking your plans, code
- making the existing restrictions more or less strict
Considerations — Changes in the Twitter APIs — Notes
Existing codes to collect tweets may or may not be affected, depending on
- how the APIs v2 will look in the end
- it is still a work in progress
- it is still a work in progress
- how the
rtweetpackage* will adopt- it is currently going through a major revision
- how the APIs v2 will look in the end
* This is the R package that we will use to collect tweets. More details are in Part 2.
Considerations — Changes in the Twitter APIs — Notes
Existing codes to collect tweets may or may not be affected, depending on
- how the APIs V2 will look in the end
- it is still a work in progress
- it is still a work in progress
- whether and how the
rtweetpackage will adopt- it is currently going through a major revision
- how the APIs V2 will look in the end
Not all changes are bad
- among others, APIs v2 introduces the Academic Research access
- 'to serve the unique needs and challenges of academic researchers'
- ranging from master's students to professors
- ranging from master's students to professors
- access to all public tweets
- by up to 10M a month at a time
- 'to serve the unique needs and challenges of academic researchers'
- among others, APIs v2 introduces the Academic Research access
Considerations — Law and Ethics
It is often impossible to get users' consent
- i.e., for collecting and analysing their data on Twitter
- Twitter itself has no problem with it, but others might disagree
- e.g., your law makers, (funding and/or research) institution, subjects, conscience
- i.e., for collecting and analysing their data on Twitter
Considerations — Law and Ethics
It is often impossible to get users' consent
- i.e., for collecting and analysing their data on Twitter
- Twitter itself has no problem with it, but others might disagree
- e.g., your law makers, (funding and/or research) institution, subjects, conscience
- i.e., for collecting and analysing their data on Twitter
Check the rules that apply to your case
- rules and regulations in your country, at your institution
Considerations — Law and Ethics
It is often impossible to get users' consent
- i.e., for collecting and analysing their data on Twitter
- Twitter itself has no problem with it, but others might disagree
- e.g., your law makers, (funding and/or research) institution, subjects, conscience
- i.e., for collecting and analysing their data on Twitter
Check the rules that apply to your case
- rules and regulations in your country, at your institution
Reflect on whether using Twitter data for research is ethical
- even where it is legal and allowed, it may not be moral
Considerations — Data Storage
Twitter data frequently requires
large amounts of digital storage space
- Twitter data is typically big data
- many tweets, up to 90 variables
- many tweets, up to 90 variables
- e.g., a dataset of 1M tweets requires about 300MB
- when stored in R data formats
- Twitter data is typically big data
Considerations — Data Storage
Twitter data frequently requires
large amounts of digital storage space
- Twitter data is typically big data
- many tweets, up to 90 variables
- many tweets, up to 90 variables
- e.g., a dataset of 1M tweets requires about 300MB
- when stored in R data formats
- Twitter data is typically big data
private, safe storage spaces
- due to Twitter Developer terms
- but also local rules, institutional requirements
Considerations — Language and Context
Some tools of text analysis are developed for a specific language and/or context
e.g., dictionaries for sentiment analysis
- might be in English, for political texts, only
these may not be useful, valid for different languages, and/or contexts
Considerations — Language and Context
Some tools of text analysis are developed for a specific language and/or context
e.g., dictionaries for sentiment analysis
- might be in English, for political texts, only
these may not be useful, valid for different languages, and/or contexts
Some tools of text analysis are developed for general use
e.g., a dictionary for sentiments in everyday language
these may not be useful, valid for a specific context
- e.g., political texts
Workshop Slides — Access on Your Browser
Having the workshop slides* on your own machine might be helpful
- flexibility to go back and forward on your own
- ability to scroll across long codes on some slides
Access at https://resulumit.com/teaching/twtr_workshop.html
- will remain accessible after the workshop
- might crash for some Safari users
- if using a different browser application is not an option, view the PDF version of the slides on GitHub
* These slides are produced in R, with the xaringan package (Xie, 2022).
Course Materials — Download from the Internet
Download the materials from https://github.com/resulumit/twtr_workshop/tree/materials
- on the webpage, follow
Code -> Download ZIP
Unzip and rename the folder
- unzip to a location that is not synced
- e.g., perhaps to Documents, but not Dropbox
- unzip to a location that is not synced
Course Materials — Overview
Materials have the following structure
twtr_workshop-materials | |- data | | | |- mps.csv | |- status_ids.rds | |- tweets.rds | |- analysis | | | |- solutions.R | |- tweets.Rmd | |- tweets_answers.Rmd | |- users.Rmd | |- users_answers.RmdCourse Materials — Contents
data/mps.csv- a dataset on the members of parliament (MPs) in the British House of Commons, at the end of January 2021
- it includes variables on electoral results as well as Twitter usernames
data/status_ids.rds- a dataset with a single variable:
status_id - lists the status IDs of all tweets posted by the MPs listed in
mps.csv, during January 2021
- a dataset with a single variable:
data/tweets.rds- similar to
data/status_ids, except that- the time period is now limited to 15 to 31 January, reducing the number of observations below 50,000, allowing for all variables to be posted online
- similar to
Course Materials — Contents
exercises/solutions.R- an R script with solutions for exercises until the end of Part 4
exercises/tweets.Rmd- an R Markdown file with exercises for Part 6
- the solution to these exercises are in
tweets_answers.Rmd
exercises/users.Rmd- an R Markdown file with exercises for Part 5
- the solution to these exercises are in
users_answers.Rmd
R — Download from the Internet and Install
Programming language of this workshop
- created for data analysis, extending for other purposes
- e.g., accessing APIs
- allows for all three steps in one environment
- collecting, processing, and analysing Twitter data
- an alternative: python
- created for data analysis, extending for other purposes
Optional, if you have R already installed
- consider updating your copy, if it is not up to date
- type the
R.version.stringcommand in R to check the version of your copy - compare with the latest official release at https://cran.r-project.org/sources.html
- type the
- consider updating your copy, if it is not up to date
Download R from https://cloud.r-project.org
- choose the version for your operating system
RStudio — Download from the Internet and Install
Optional, but highly recommended
- facilitates working with Twitter data in R
A popular integrated development environment (IDE) for R
- an alternative: GNU Emacs
Download RStudio from https://rstudio.com/products/rstudio/download
- choose the free version
- consider updating your copy, if it is not up to date, following from the RStudio menu:
Help -> Check for Updates
RStudio Project — Create from within RStudio
RStudio allows for dividing your work with R into separate projects
- each project gets dedicated workspace, history, and source documents
- this page has more information on why projects are recommended
- Create a new RStudio project for the existing* workshop directory
...\twtr_workshop-materialsfrom the RStudio menu:
File -> New Project -> Existing Directory -> Browse -> ...\twtr_workshop-materials -> Open
* Recall that we have downloaded this earlier from GitHub. Back to the relevant slide.
R Packages — Install from within RStudio*
install.packages(c("rtweet", "httpuv", "tidyverse", "tidytext"))* You may already have a copy of one or more of these packages. In that case, I recommend updating by re-installing them now.
R Packages — Install from within RStudio
install.packages(c("rtweet", "httpuv", "tidyverse", "tidytext"))rtweet(Kearney, 2020), for collecting tweets- alternatives:
academictwitteRfor academic research access; running Python code in R
- alternatives:
R Packages — Install from within RStudio
install.packages(c("rtweet", "httpuv", "tidyverse", "tidytext"))rtweet(Kearney, 2020), for collecting tweets- alternatives:
academictwitteRfor academic research access; running Python code in R
- alternatives:
httpuv(Cheng and Chang, 2022), for API authorization- alternative: using your own access tokens
- necessitates making an application through a developer
- has advantages that we will discuss later on
- alternative: using your own access tokens
R Packages — Install from within RStudio
install.packages(c("rtweet", "httpuv", "tidyverse", "tidytext"))tidyverse(Wickham, 2021), for various tasks- including data manipulation, visualisation
- alternative: e.g.,
baseR
R Packages — Install from within RStudio
install.packages(c("rtweet", "httpuv", "tidyverse", "tidytext"))tidyverse(Wickham, 2021), for various tasks- including data manipulation, visualisation
- alternative: e.g.,
baseR
tidytext(Robinson and Silge, 2021), for working with text as data- alternative: e.g.,
quanteda
- alternative: e.g.,
Twitter — Authorisation
Authorization to use Twitter APIs requires at least three steps*
1) open a user account on Twitter
- a personal or an institutional (perhaps, for a research project) one
- done once, takes minutes
2) with that user account, apply for a developer account
- so that you are recognised as a developer, have access to the developer portal
- done once per account, takes days to get approved manually
3) with that developer account, register a Twitter app
- so that you have the keys and tokens for authorisation
- repeated for every project, takes minutes
* There may be additional steps, such as registering for the Academic Research access.
Twitter — Authorisation — Notes
It is possible to interact with Twitter APIs without steps 2 and 3
rtweethas a its own Twitter app —rstats2twitter— that anyone can use- anyone with a Twitter account, who authorises
rstats2twittervia a pop-up browser
- anyone with a Twitter account, who authorises
Twitter — Authorisation — Notes
It is possible to interact with Twitter APIs without steps 2 and 3
rtweethas a its own Twitter app —rstats2twitter— that anyone can use- anyone with a Twitter account, who authorises
rstats2twittervia a pop-up browser
- anyone with a Twitter account, who authorises
I recommend
- following only the step 1 (open an account) now, which
- you might already have done
- is otherwise automatic
- allows us to use
rstats2twitterand follow the workshop
- leaving the remaining steps until after the workshop
- to allow you to think and write your applications carefully
- to get my feedback if you prefer to do so
- following only the step 1 (open an account) now, which
Twitter — Open an Account
Sign up for Twitter at https://twitter.com/
a pre-condition for interacting with Twitter APIs
- e.g., you must be authorized
- even to use
rtweet's app —rstats2twitter
- even to use
- e.g., you must be authorized
helpful for getting to know what you study
- e.g., the written and unwritten rules that mediate the behaviour on Twitter
- as discussed in Part 1
- e.g., the written and unwritten rules that mediate the behaviour on Twitter
with a strategic username
- usernames are changeable, but nevertheless public
- either choose an anonymous username (e.g.,
asdf029348) - or choose one carefully — they become a part of users' online presence
- either choose an anonymous username (e.g.,
- usernames are changeable, but nevertheless public
Twitter — Apply for a Developer Account
- On developer.twitter.com, click
Apply- at the top-right corner of the page*
- follow the instructions on consecutive pages
*It takes a few days for Twitter to review and hopefully approve your request to have an account. You might have created an account before. In that case, you will see Developer Portal instead of Apply.
Twitter — Apply for a Developer Account
- On developer.twitter.com, click
Apply- at the top-right corner of the page*
- follow the instructions on consecutive pages
- Write a detailed case for your intended use of Twitter APIs
- not just that you are attending this workshop
- a quick application is likely to slow the review process
- as Twitter often asks for more details via email
- rejection is also a possibility
- Carefully review the Twitter's Developer Agreement and Policy
- especially important if you will develop an app that
- others will use
- will write as well as read Twitter data
- especially important if you will develop an app that
Twitter — Register an App
On developer.twitter.com/en/portal/projects-and-apps, click
+ Create Appfollow the instructions on consecutive pages
- you will need a unique name for your app
note that, once the app is registered, you are provided with keys and tokens
- you will use these for authentication
- if you choose not to authenticate through
rtweet's own app, calledrstats2twitter - more on this in Part 3
- if you choose not to authenticate through
- you will use these for authentication
does not mean you have to create an actual app
- e.g., an app for smart phones
Twitter — Keys and Tokens — Notes
- Keys and tokens are personal
- should not be shared with others
- e.g., through replication files, when asking a question on Stack Overflow
- should not be shared with others
Twitter — Keys and Tokens — Notes
- Keys and tokens are personal
- should not be shared with others
- e.g., through replication files, when asking a question on Stack Overflow
- should not be shared with others
- Keys and tokens can be re-generated anytime
- on your applications page, under the
Keys and tokenstab - this requires updating your R script with the new tokens as well
- on your applications page, under the
Twitter — Keys and Tokens — Notes
- Keys and tokens are personal
- should not be shared with others
- e.g., through replication files, when asking a question on Stack Overflow
- should not be shared with others
Keys and tokens can be re-generated anytime
- on your applications page, under the
Keys and tokenstab - this requires updating your R script with the new tokens as well
- on your applications page, under the
Twitter allows for further, optional settings involving keys and tokens
- relevant, mostly, for apps to do more than just collecting tweets
- e.g., settings for 3-legged OAuth
- like
rstats2twitter, to allow for other users to authenticate through a browser pop up
- like
- not covered in this workshop
Twitter — Keys and Tokens — Notes — Definitions
Consumer key and Consumer secret
- identifiers for an application
- provide project authorization
- identify the application
- check whether the application has been granted access
- like your application's username and password
Twitter — Keys and Tokens — Notes — Definitions
Consumer key and Consumer secret
- identifiers for an application
- provide project authorization
- identify the application
- check whether the application has been granted access
- like your application's username and password
Access token and Access token secret
- identifier for users of an application
- this may or may not include anyone other than the owner
- e.g., for
rstats2twitter, there are many users
- provide user authentication
- identify the user
- check whether the user should have access to a request
- identifier for users of an application
Data Collection — Authentication
There are two different methods of authentication
through
rtweet'srstats2twitterapp- the app makes requests on your behalf
- you simply approve this, via a browser that pops up
- nice and easy, but comes with some limitations
Data Collection — Authentication
There are two different methods of authentication
through
rtweet'srstats2twitterapp- the app makes requests on your behalf
- you simply approve this, via a browser that pops up
- nice and easy, but comes with some limitations
through your own app
- you make requests on your behalf
- through your own app that you register as a developer
- takes a little effort, but comes with additional stability and functionality
- removing the dependency on
rstats2twitter, over which you have no control - getting rid of the pop up windows
- not only for collecting tweets, but also posting your own tweets
- and, reading and writing your own direct messages
- removing the dependency on
Data Collection — Define Your Token
If you are using your own app to authenticate, create a token
- using the
create_tokenfunction - the
appargument requires for the name of your own app, as registered on developer.twitter.com - the other arguments to be filled with the information from the
Keys and tokenstab on the same website
tw_token <- create_token( app = "", consumer_key = "", consumer_secret = "", access_token = "", access_secret = "" )Data Collection — Define Your Token — Alternatives
You may wish to put your keys and tokens elsewhere
- they are personal, just like a password
There are at least two alternatives
- create a separate script, which you can then
sourceat the top of your main script
- create a separate script, which you can then
keys_tokens.R
tw_token <- create_token( app = "", consumer_key = "", consumer_secret = "", access_token = "", access_secret = "" )data_collection.R
library(rtweet) source("keys_tokens.R")Data Collection — Define Your Token — Alternatives
You may wish to put your keys and tokens elsewhere
- they are personal, just like a password
There are at least two alternatives
create a separate script, which you can then
sourceat the top of your main scriptstore your keys and tokens in your
.Renvironfile, which can be created at the project level as well
.Renviron
TWITTER_APP=name_of_my_appTWITTER_CONSUMER_KEY=akN...TWITTER_CONSUMER_SECRET=HJK...TWITTER_ACCESS_TOKEN=345...TWITTER_ACCESS_SECRET=SDF...data_collection.R
library(rtweet)tw_token <- create_token( app = Sys.getenv("TWITTER_APP"), consumer_key = Sys.getenv("TWITTER_CONSUMER_KEY"), consumer_secret = Sys.getenv("TWITTER_CONSUMER_SECRET"), access_token = Sys.getenv("TWITTER_ACCESS_TOKEN"), access_secret = Sys.getenv("TWITTER_ACCESS_SECRET") )Other Resources*
R for Data Science (Wickham and Grolemund, 2021)
- open access at https://r4ds.had.co.nz
Other Resources*
R for Data Science (Wickham and Grolemund, 2021)
- open access at https://r4ds.had.co.nz
Text Mining with R: A Tidy Approach (Silge and Robinson, 2017)
- open access at tidytextmining.com
- comes with a course website where you can practice
Other Resources*
R for Data Science (Wickham and Grolemund, 2021)
- open access at https://r4ds.had.co.nz
Text Mining with R: A Tidy Approach (Silge and Robinson, 2017)
- open access at tidytextmining.com
- comes with a course website where you can practice
A Tutorial for Using Twitter Data in the Social Sciences: Data Collection, Preparation, and Analysis (Jürgens and Jungherr, 2016)
- open access at http://dx.doi.org/10.2139/ssrn.2710146
* I recommend these to be consulted not during but after the workshop.
Data Collection — Overview — APIs
We will collect data through APIs
- i.e., Twitter's Standard v1.1 APIs
- provides more variables than available through browsers
- comes with rules and restrictions
- enforced through authentication
Data Collection — Overview — APIs
We will collect data through APIs
- i.e., Twitter's Standard v1.1 APIs
- provides more variables than available through browsers
- comes with rules and restrictions
- enforced through authentication
Collecting data through web scraping is also possible
- e.g., with
GetOldTweets3— a python library- scrapes, scrolls down, and scrapes again to collect all matching data
- scrapes, scrolls down, and scrapes again to collect all matching data
- does not require, is not limited by, Twitter APIs
- limited with what is available on browsers
- may or may not be ethical and/or legal
- e.g., with
Data Collection — Overview — APIs — Types
In general, there are two main types of APIs
- REST and Streaming
- applies to APIS elsewhere, not just at Twitter
- functions, arguments, behaviour differ slightly
Data Collection — Overview — APIs — Types
In general, there are two main types of APIs
- REST and Streaming
- applies to APIS elsewhere, not just at Twitter
- functions, arguments, behaviour differ slightly
REST APIs are for single, one-off requests
- e.g., search for tweets posted in the last 6 to 9 days
- but also, post or delete tweets
Data Collection — Overview — APIs — Types
In general, there are two main types of APIs
- REST and Streaming
- applies to APIS elsewhere, not just at Twitter
- functions, arguments, behaviour differ slightly
REST APIs are for single, one-off requests
- e.g., search for tweets posted in the last 6 to 9 days
- but also, post or delete tweets
Streaming APIs are for continuous requests
- e.g., collect tweets as they are being posted
Data Collection — Overview — APIs — Types
At Twitter, there is a further differentiation among the APIs
- e.i., API v2, Enterprise: Gnip 2.0, Premium v1.1, Standard v1.1
- with each, you can make single or continuous requests
Data Collection — Overview — APIs — Types
At Twitter, there is a further differentiation among the APIs
- e.i., API v2, Enterprise: Gnip 2.0, Premium v1.1, Standard v1.1
- with each, you can make single or continuous requests
Rules and restrictions differ from one type to another
- as does the cost
- some remove the restrictions on how much data we can access
- restrictions on how quickly we can access data exist in all types
- these restrictions are called rate limits
Data Collection — Overview — APIs — Types
At Twitter, there is a further differentiation among the APIs
- e.i., API v2, Enterprise: Gnip 2.0, Premium v1.1, Standard v1.1
- with each, you can make single or continuous requests
Rules and restrictions differ from one type to another
- as does the cost
- some remove the restrictions on how much data we can access
- restrictions on how quickly we can access data exist in all types
- these restrictions are called rate limits
Rules and restrictions can also differ within one type
- for different operations
- e.g., for collecting historical vs. live data
- for different operations
Data Collection — Overview — Standard v1.1 APIs
We will collect data through Twitter's Standard v1.1 APIs
- free of charge
- thanks to
rweet'srstats2twitterapp, can be used immediately - comes with the strictest of restrictions
- e.g., searches tweets posted in the last 6 to 9 days
Data Collection — Overview — Standard v1.1 APIs
We will collect data through Twitter's Standard v1.1 APIs
- free of charge
- thanks to
rweet'srstats2twitterapp, can be used immediately - comes with the strictest of restrictions
- e.g., searches tweets posted in the last 6 to 9 days
You can surpass these restrictions later on
- academic researchers can apply for Academic Research access
- others can purchase an alternative
- the principles of data collection are likely to remain the same
rweethas thesearch_30dayandsearch_fullarchivefunctions for the Premium V1.1 APIs- the package may require an update, in line with the Academic Research access
Data Collection — Overview — APIs — Limitations
Our attempts to collect data will be limited for various reasons, including
- the intended restrictions by Twitter
- by the limitations of Standard v1.1
- e.g., by rate limits
- maximum number of requests
- per app, type of request, time interval
- e.g., by rate limits
- by the limitations of Standard v1.1
Data Collection — Overview — APIs — Limitations
Our attempts to collect data will be limited for various reasons, including
- the intended restrictions by Twitter
- by the limitations of Standard v1.1
- e.g., by rate limits
- maximum number of requests
- per app, type of request, time interval
- e.g., by rate limits
- by the limitations of Standard v1.1
- any lack of tweets or users matching our search criteria
- stricter the criteria, more likely to occur
Data Collection — Overview — APIs — Limitations
Our attempts to collect data will be limited for various reasons, including
- the intended restrictions by Twitter
- by the limitations of Standard v1.1
- e.g., by rate limits
- maximum number of requests
- per app, type of request, time interval
- e.g., by rate limits
- by the limitations of Standard v1.1
- any lack of tweets or users matching our search criteria
- stricter the criteria, more likely to occur
- connections timing out
- depends on type of requests, and your internet connection
- more likely for continuous searches
Data Collection — Overview — APIs — Limitations
Our attempts to collect data will be limited for various reasons, including
- the intended restrictions by Twitter
- by the limitations of Standard v1.1
- e.g., by rate limits
- maximum number of requests
- per app, type of request, time interval
- e.g., by rate limits
- by the limitations of Standard v1.1
- any lack of tweets or users matching our search criteria
- stricter the criteria, more likely to occur
- connections timing out
- depends on type of requests, and your internet connection
- more likely for continuous searches
- reasons unknown to humankind
- sometimes things just happen
Data Collection — rtweet — Overview
A powerful R package for collecting Twitter data
- created by Michael W. Kearney (University of Missouri)
- used widely, replacing previous packages for this task
- e.g.,
twitteR
- e.g.,
- last updated on CRAN two years ago
- the package is currently being updated on GitHub
Data Collection — rtweet — Overview
A powerful R package for collecting Twitter data
- created by Michael W. Kearney (University of Missouri)
- used widely, replacing previous packages for this task
- e.g.,
twitteR
- e.g.,
- last updated on CRAN two years ago
- the package is currently being updated on GitHub
A lot has already been written on this package. See, for example,
- the package repository on GitHub
- the package documentation
- this journal article by its creator
- this book by Bob Rudis — a user of the package
- numerous tutorials, such as this, this, and this
Data Collection — rtweet — Overview
A powerful R package for collecting Twitter data
- created by Michael W. Kearney (University of Missouri)
- used widely, replacing previous packages for this task
- e.g.,
twitteR
- e.g.,
- last updated on CRAN two years ago
- the package is currently being updated on GitHub
A lot has already been written on this package. See, for example,
- the package repository on GitHub
- the package documentation
- this journal article by its creator
- this book by Bob Rudis — a user of the package
- numerous tutorials, such as this, this, and this
- Comes with its own app,
rstats2twitter- allows for collecting tweets without a developer account
- offers the option of using your own keys and tokens, if/once you have them
Data Collection — rtweet — Basics
There are four main groups of functions to collect historical data, starting with
search_- such as
search_tweetsorsearch_users - 4 functions, for general use
- 2 for standard APIs, 2 for premium APIs
- such as
Data Collection — rtweet — Basics
There are four main groups of functions to collect historical data, starting with
search_- such as
search_tweetsorsearch_users - 4 functions, for general use
- 2 for standard APIs, 2 for premium APIs
- such as
lookup_- such as
lookup_tweetsorlookup_users - 5 functions, for expanding an existing variable into a dataset
- e.g., starting with a list of IDs for tweets or users
- such as
Data Collection — rtweet — Basics
There are four main groups of functions to collect historical data, starting with
search_- such as
search_tweetsorsearch_users - 4 functions, for general use
- 2 for standard APIs, 2 for premium APIs
- such as
lookup_- such as
lookup_tweetsorlookup_users - 5 functions, for expanding an existing variable into a dataset
- e.g., starting with a list of IDs for tweets or users
- such as
get_- such as
get_followersorget_friends - 11 functions, for specific tasks
- such as
Data Collection — rtweet — Basics
There are four main groups of functions to collect historical data, starting with
search_- such as
search_tweetsorsearch_users - 4 functions, for general use
- 2 for standard APIs, 2 for premium APIs
- such as
lookup_- such as
lookup_tweetsorlookup_users - 5 functions, for expanding an existing variable into a dataset
- e.g., starting with a list of IDs for tweets or users
- such as
get_- such as
get_followersorget_friends - 11 functions, for specific tasks
- such as
lists_- such as
lists_membersorlists_statuses - 6 functions, for tasks related to Twitter lists specifically
- such as
Data Collection — rtweet — Basics
There is also one function to collect tweets in real time
stream_tweets- queries the streaming API
- returns a small random sample of all tweets as they are posted
- can be filtered by keywords, users, and/or locations
Data Collection — rtweet — Basics
There is also one function to collect tweets in real time
stream_tweets- queries the streaming API
- returns a small random sample of all tweets as they are posted
- can be filtered by keywords, users, and/or locations
For other functions, see the package documentation
- e.g., the functions starting with
post_- allowing for posting your tweets, direct messages, from within R
- e.g., the functions starting with
Data Collection — Start Your Script
Check that you are in the right project
- created in Part 2
- indicated at the upper-right corner of RStudio window
Create a new R Script, following from the RStudio menu
File -> New File -> R Script
- Name and save your file
- to avoid the
Untitled123problem - e.g.,
data_collection.R
- to avoid the
- Load the
rtweetand other packages- no need to load the
httpuvpackage, enough if installed
- no need to load the
library(rtweet)library(tidyverse)library(tidytext)search_
Data Collection — search_tweets
Collect tweets posted in the last 6 to 9 days
filter by search query, with the
qargumentlimited to 18,000 tweets, per 15 minutes, per token*
- set the limit, higher or lower, with the
nargument**- works best the multiples of 100
- works best the multiples of 100
- if set higher, wait automatically by setting the
retryonratelimitargument toTRUE
- set the limit, higher or lower, with the
search_tweets(q, n = 100, type = "recent", include_rts = TRUE, geocode = NULL, max_id = NULL, parse = TRUE, token = NULL, retryonratelimit = FALSE, verbose = TRUE, ...)* All limits are for the standard v1.1 APIs.
**This argument is common to many functions in the package. I recommend setting it to a small number, such as 200, for the exercises in this workshop. This will save computation time and avoid running into rate limits.
Data Collection — search_tweets
- Collect the latest 100 tweets that
- include the hashtag "publish"
- Note that
- by default,
type = "recent", returning the latest tweets- other options are "popular" and "mixed"
- other options are "popular" and "mixed"
- by default,
n = 100, returning 100 tweets - here we are relying on
rtweet'srstats2twitterapp- as, by default,
token = NULL
- as, by default,
- by default,
search_tweets(q = "#publish")Exercises
1) Collect the latest 30 tweets that
- include the hashtag "AcademicTwitter"
- and assign the resulting data frame to
df_tweets- so that you can observe the results with ease
- hence, I recommend doing the same for all APIs searches that follow
2) Observe how the rstats2twitter app works
- when you call the function, pay attention to what happens on your R console and on your default browser
- this will happen only once per R session
3) Take some time to explore the data frame
- see which variables are in there, and how they are called
- think about how you could use these variables for research
- hint: use functions like
View,str,names,tibble::glimpse
4) Conduct the same search on a browser
- using the advanced search form
- compare and contrast the API- and browser-based searches
15:00
Data Collection — Notes
Twitter usernames, or handles, are stored under variable
screen_name- can be misleading, as users also have display names
Data Collection — Notes
Twitter usernames, or handles, are stored under variable
screen_name- can be misleading, as users also have display names
Twitter allows user to change their usernames and display names
- user IDs, however, do not change
user_idis a better variable for reproducible research
- user IDs, however, do not change
Data Collection — Notes
Twitter usernames, or handles, are stored under variable
screen_name- can be misleading, as users also have display names
Twitter allows user to change their usernames and display names
- user IDs, however, do not change
user_idis a better variable for reproducible research
- user IDs, however, do not change
The date and time data are matched to Greenwhich Mean Time
- stored under the variable
created_at - no matter where users actually are at the time of tweeting
- stored under the variable
Data Collection — Notes
Twitter usernames, or handles, are stored under variable
screen_name- can be misleading, as users also have display names
Twitter allows user to change their usernames and display names
- user IDs, however, do not change
user_idis a better variable for reproducible research
- user IDs, however, do not change
The date and time data are matched to Greenwhich Mean Time
- stored under the variable
created_at - no matter where users actually are at the time of tweeting
- stored under the variable
You may wish to exclude retweets
- depending on the research question and design
- by setting
include_rts = FALSE
Data Collection — search_tweets
Collect the top 200 tweets that
- include the word "publish"
search_tweets(q = "publish", n = 200, type = "popular")Data Collection — search_tweets
Collect the top 200 tweets that
- include the word "publish" and "perish", not necessarily in that order
Note that
- space is treated as the boolean AND operator
search_tweets(q = "publish perish", n = 200, type = "popular")Data Collection — search_tweets
Collect the top 200 tweets that
- include the word "publish" or "perish"
Note that
- the boolean OR operator must be specified, in capital letters
search_tweets(q = "publish OR perish", n = 200, type = "popular")Data Collection — search_tweets
Collect the top 200 tweets that
- include the exact phrase "publish or perish"
Note that
- double quotation marks " need to be escaped with a backslash \
search_tweets(q = "\"publish or perish\"", n = 200, type = "popular")Data Collection — search_tweets
Collect the top 200 tweets that
- include "publish" but not "perish"
Note that
- words can be negated with a hyphen -
search_tweets(q = "publish -perish", n = 200, type = "popular")Data Collection — search_tweets
Collect the top 200 tweets that
- include "publish", and
- are otherwise written in German
search_tweets(q = "publish lang:de", n = 200, type = "popular")Note that
- query parameters, such as
lang, are followed by a colon :- other parameters include
filter,from,to,since,until,min_retweetsetc.
- other parameters include
- there is an official guide for a comprehensive but not complete list of search operators
- alternatively, fill in this advanced search form, and observe the resulting syntax
- query parameters, such as
Data Collection — search_tweets
Collect the top 200 tweets that
- include "publish", and
- are not in German
Note that
- operators can be negated with a hyphen as well
search_tweets(q = "publish -lang:de", n = 200, type = "popular")Data Collection — search_tweets — Notes
- Some query parameters can be passed into the function as arguments as well
- e.g.,
lang,filter
- e.g.,
- Note that
- these functions on the right return the same observations
- there are slight differences in syntax, such as
lang:enas a parameterlang = "en"as an argument
search_tweets(q = "publish lang:en filter:replies", n = 200, type = "mixed")search_tweets(q = "publish", n = 200, type = "mixed", lang = "en", filter = "replies")Data Collection — search_tweets — Notes
This function returns a data frame
- as do many other functions in the package
- because, by default,
parse = TRUE
Under the hood, Twitter APIs return nested lists
- nested lists can be tidied into rectangular shape, but not tidy data as they are returned
rtweetdoes most of the data preparation for us
Exercises
5) Collect the latest 10 tweets that include
- the phrase "publish or perish"
- and the word "academia" but not the word "PhD"
6) Collect the most popular 50 tweets that
- include the word "Switzerland"
- excluding retweets
- note that Twitter API may return fewer than 50 tweets
- as there may not be that many popular tweets posted in the last 6 to 9 days
7) Collect the most recent 35,000 tweets that
- include the word "PhD"
- note that this is over the limit of 18,000
- hint: pull the help file for the function to see which argument you must use to surpass the limit
20:00
Data Collection — search_users
Collect information on users
- filter usernames, names, bios
- by search query with the
qargument - returns information from recently active users
- limited to 1,000 users
search_users(q, n = 100, parse = TRUE, token = NULL, verbose = TRUE)Note that
- there is no
retryonratelimitargument - you can still use the complete list of search operators and this advanced search form for help with queries
- there is no
Exercises
8) Collect information on 30 users that
- are associated with the word "PhD", but not with the word "rstats"
- read one of these users' bio on their homepage via a browser
9) Collect the latest 30 tweets that
- include the word "PhD"
- but not the word "rstats"
10) Take some time to explore the resulting data frames
- how do they compare to each other?
11) Conduct one or more searches that interest you
- for tweets and/or users
20:00
Data Collection — Notes — rate_limit
Check rate limits at any time
- for all operations
- for a specific operation
- e.g., searching tweets with the
search_tweetsfunction
- e.g., searching tweets with the
rate_limit(token = NULL, query = NULL, parse = TRUE)Note that
- these limits are for the number of requests, per user and/or per app
- if no token is specified, the function uses the
rstats2twitterapp - rate limits decrease as you use them, increase again after a time threshold
- Twitter Developer terms do not allow for multiple tokens to be used for the same project
Data Collection — Notes — rate_limit
Check you remaining rate limits, for all operations
rate_limit()# A tibble: 261 x 7 query limit remaining reset reset_at timestamp app <chr> <int> <int> <drtn> <dttm> <dttm> <chr> 1 lists/list 15 15 14.78 mins 2022-03-06 10:35:45 2022-03-06 10:20:59 rstats2twitter 2 lists/:id/tweets&GET 900 900 14.78 mins 2022-03-06 10:35:45 2022-03-06 10:20:59 rstats2twitter 3 lists/:id/followers&GET 180 180 14.78 mins 2022-03-06 10:35:45 2022-03-06 10:20:59 rstats2twitter 4 lists/memberships 75 75 14.78 mins 2022-03-06 10:35:45 2022-03-06 10:20:59 rstats2twitter 5 lists/:id&DELETE 300 300 14.78 mins 2022-03-06 10:35:45 2022-03-06 10:20:59 rstats2twitter 6 lists/subscriptions 15 15 14.78 mins 2022-03-06 10:35:45 2022-03-06 10:20:59 rstats2twitter 7 lists/members 900 900 14.78 mins 2022-03-06 10:35:45 2022-03-06 10:20:59 rstats2twitter 8 lists/:id&GET 75 75 14.78 mins 2022-03-06 10:35:45 2022-03-06 10:20:59 rstats2twitter 9 lists/subscribers/show 15 15 14.78 mins 2022-03-06 10:35:45 2022-03-06 10:20:59 rstats2twitter10 lists/:id&PUT 300 300 14.78 mins 2022-03-06 10:35:45 2022-03-06 10:20:59 rstats2twitter# ... with 251 more rowsData Collection — Notes — rate_limit
Check your remaining rate limits for specifically the search_tweets function
rate_limit(query = "search/tweets")# A tibble: 1 x 7 query limit remaining reset reset_at timestamp app <chr> <int> <int> <drtn> <dttm> <dttm> <chr> 1 search/tweets 180 171 14.77129 mins 2022-03-06 10:42:12 2022-03-06 10:27:26 rstats2twitterData Collection — Notes — rate_limit
Single out the number of remaining rate limit for specifically the search_tweets function
rate_limit(query = "search/tweets")$remaining## [1] 171Note that
- this is not the number of tweets you can search for
- but rather the number of times that you can search for tweets
Exercises
12) Check all your remaining rate limits
- have a look at the resulting data
13) Check your remaining limits for the search_tweets function
- assign it to a name
14) Collect the most recent 50 tweets that
- include the word "rstat"
- and posted in English
15) Check your remaining limits for the search_tweets function again
- how do they compare to the results from Exercise 13?
10:00
lookup_
Data Collection — lookup_tweets
Collect data on one or more tweets
- whose status ID you already know
- limited with 90,000 posts per 15 minutes
- there is no
retryonratelimitargument
- there is no
lookup_tweets(statuses, parse = TRUE, token = NULL)Note that
- this function would be useful for replicating studies
- status IDs are visible on browsers
- if you click on a specific tweet
Data Collection — lookup_tweets
Collect data on one or more status IDs
lookup_tweets(statuses = c("567053242429734913", "266031293945503744", "440322224407314432"))Data Collection — lookup_tweets
Collect data on one or more status IDs
lookup_tweets(statuses = c("567053242429734913", "266031293945503744", "440322224407314432"))Collect data on status IDs in a data frame
lookup_tweets(statuses = df$status_id)Data Collection — lookup_users
Collect data on one or more users
- whose user ID or username you already know
- limited with 90,000 users per 15 minutes
- there is no
retryonratelimitargument
- there is no
Note that
- usernames can change
- rely on user IDs where possible
lookup_users(users, parse = TRUE, token = NULL)Data Collection — lookup_users
Collect data on one or more status IDs
lookup_users(users = c("drob", "hadleywickham", "JennyBryan"))Data Collection — lookup_users
Collect data on one or more status IDs
lookup_users(users = c("drob", "hadleywickham", "JennyBryan"))Collect data on status IDs in a data frame
lookup_users(users = df$screen_name)Data Collection — lookup_friendships
Collect data on friendship status of two users
- e.g., whether they follow each other
- whose user ID or username you already know
- limited with 90,000 users per 15 minutes
- there is no
retryonratelimitargument
- there is no
Note that
- usernames can change
- rely on user IDs where possible
lookup_friendships(source, target, parse = TRUE, token = NULL)Exercises
16) Find a status ID through your browser and look it up in R
- they appear in search bar when viewing a single tweet
- unlike user IDs
17) Look up a subset of tweets whose ids stored in status_ids.rds
18) Look up a subset of users whose usernames stored in mps.csv
19) Check the friendship status of two MPs in the dataset
- hint: not all MPs are on Twitter, but most are
- e.g., check if the 10th and 20th observations follow each other
15:00
get_
Data Collection — get_timeline
Collect the latest posts from one or more users
- specified by username or user IDs, with the
userargument - limited to 3,200 tweets per user-timeline
- there is no
retryonratelimitargument
- there is no
- returns the most recent only, if there is more
- specified by username or user IDs, with the
get_timeline(user, n = 100, max_id = NULL, home = FALSE, parse = TRUE, check = TRUE, token = NULL, ...)Data Collection — get_timeline
Collect the most recent 200 tweets by David Robinson
- e.i., tweets from the user-timeline of one user
get_timeline(user = "drob", n = 200)Data Collection — get_timeline
Collect the most recent posts by David Robinson and Hadley Wickham
- tweets from the user-timeline of multiple users
Note that
- this results in a dataframe of 400 observations
- 200 from each specified user
- with increasing number of users, you are likely to run out of rate limit
get_timeline(user = c("drob", "hadleywickham"), n = 200)Data Collection — get_timeline — Home Timeline
The package documentation suggests that
get_timelinecan also retrieve home-timelines- i.e., the tweets that appear on a given user's home, as posted by accounts followed by that user
- if the
homeargument is set toTRUE
- if the
- i.e., the tweets that appear on a given user's home, as posted by accounts followed by that user
This does not seem to be true
- this code returns your home-timeline, not Wickham's
- from the last 6 to 9 days
- the
userargument is ignored whenhome = TRUE - but the
userargument cannot be missing
- this code returns your home-timeline, not Wickham's
get_timeline(user = "hadleywickham", n = 200, home = TRUE)Data Collection — Notes — retryonratelimit
the
retryonratelimitargument is not available for all functions in the package- e.g.,
search_users - does not mean you will not run into limits
- e.g.,
Data Collection — Notes — retryonratelimit
the
retryonratelimitargument is not available for all functions in the package- e.g.,
search_users - does not mean you will not run into limits
- e.g.,
You can create your own safety net
- e.g., with loops, where the system sleeps between iterations
- until a specific rate limit increases
- e.g., with loops, where the system sleeps between iterations
Data Collection — Notes — retryonratelimit — Iteration
datalist <- list() # create an empty list, to be filled laterfor(i in 1:length(df_users$screen_name)) { # for one user, in the data frame df_users, at a time if (rate_limit(query = "application/rate_limit_status", token = tw_token)$remaining > 2 & rate_limit(query = "get_timeline", token = tw_token)$remaining > 20) { # if your are still under rate limit for this task dat <- get_timeline(df$screen_name[i], n = 3200, # collect the tweets token = tw_token) datalist[[i]] <- dat # fill the list with data, for one user at a time }else{ # if there is no limit, wait a little wait <- rate_limit(query = "get_timeline")$reset + 0.1 Sys.sleep(wait * 60) }}df_tweets <- as.data.frame(do.call(rbind, datalist)) # put all data in one data frameExercises
20) Collect the most recent tweets posted by three users
- 10 from the first user, 20 from the second, and 30 from the third
- hint: see the function documentation on how to vary the
nargument by user
21) Collect as many tweets as possible from your own home-timeline
22) Collect data from timelines of the first five MPs in mps.csv
- collect as many tweets as possible
10:00
Data Collection — get_followers
Collect a list of followers, following one user
- returns a single column of user IDs, not usernames
- limited with 75,000 followers per 15 minutes
- use
retryonratelimit = TRUEto surpass the limit
- use
Note that
- this function does not accept multiple users
- it can be combined with
lookup_usersif usernames are needed
get_followers(user, n = 5000, page = "-1", retryonratelimit = FALSE, parse = TRUE, verbose = TRUE, token = NULL)Data Collection — get_followers
Collect a list of Hadley Wickham's followers on Twitter
get_followers(user = "hadleywickham", n = 10000, retryonratelimit = TRUE)Data Collection — get_friends
Get a list of users, followed by one or more users
- this returns a single column of user IDs, not usernames
- limited to 15 users
- use
retryonratelimit = TRUEto surpass the limit
- use
- limited also to 5,000 followers per user
- here
retryonratelimit = TRUEdoes not help
- here
- use the
pageargument instead to surpass the limit- learn the correct value with the
next_cursorfunction
- learn the correct value with the
get_friends(users, n = 5000, retryonratelimit = FALSE, page = "-1", parse = TRUE, verbose = TRUE, token = NULL)Data Collection — get_friends
Collect a list of users followed by Jenny Bryan and Hadley Wickham on Twitter
- with 20 friends from each
get_friends(users = c("hadleywickham", "JennyBryan"), n = 20)Exercises
23) Collect a list of accounts following Universität Luzern
- search for the Unversity's username with
search_users - search for the followers
get_followers
24) Collect a list of accounts that Universität Luzern follows
- and find out more about these accounts with
lookup_users
25) Check your rate limits
- see the ones that are getting low
07:30
Data Collection — get_favorites
Collect tweets liked by one or more users
- by username or user IDs, with the
userargument - limited to 3,000 likes
- there is no
retryonratelimitargument
- there is no
- returns the most recent only, if there is more
get_favorites(user, n = 200, since_id = NULL, max_id = NULL, parse = TRUE, token = NULL)Data Collection — get_favorites
Collect a list of tweets liked by Jenny Bryan
get_favorites(user = "JennyBryan")Data Collection — get_retweets
Collect information on the retweets of one tweet
- using the
status_idargument - available in the data frames returned by many functions in the package
- e.g.,
get_timeline - also available on browsers
- e.g.,
- limited to 100 retweets
- even if there might be more
- using the
get_retweets(status_id, n = 100, parse = TRUE, token = NULL, ...)Data Collection — get_retweets
Collect the most recent 50 retweets
- of the post announcing the Academic Research Access
get_retweets(status_id = "1354143047324299264")Exercises
26) Collect a list of favorites by three users
- compare and contrast the resulting data with the same information available on browser
27) Collect a list of accounts retweeting a tweet of yours
- compare and contrast the resulting data with what you can see on a browser
07:30
Data Collection — get_trends
Collect information on twitter trends
- by town or country, specified with
- the
woeidargument,* or - the
latandlongarguments
- the
- by town or country, specified with
Note that
- not all locations have trending data
- use the
trends_availablefunction to check availability- with no argument
get_trends(woeid = 1, lat = NULL, lng = NULL, exclude_hashtags = FALSE, token = NULL, parse = TRUE)* It stands for "where on earth identifier", which is 44418 for London. Google for more!
Data Collection — get_trends
Collect the trends data for London
- using the
woeidargument
get_trends(woeid = 44418)Collect the same trends data for London
- using the
latandlongarguments instead
get_trends(lat = "51.50", lng = "0.12")Exercises
28) Collect a list of places where the trends data is available
- hint: use the
trends_availablefunction
29) Collect the lists of trends for two locations
- compare and contrast the resulting data for two locations
30) Collect the list of trends for your location
- compare and contrast the resulting data with what you see on your browser
07:30
lists_
Data Collection — lists_memberships
Collect data on lists, where one or more users are listed
- i.e., the lists where a user appears
- limited to 200 lists
lists_memberships(user = NULL, n = 200, cursor = "-1", filter_to_owned_lists = FALSE, token = NULL, parse = TRUE, previous_cursor = NULL)Data Collection — lists_memberships
Collect data on lists where Jenny Bryan is listed
lists_memberships(user = "JennyBryan")Collect data on lists where Jenny Bryan or Hadley Wickham is listed
lists_memberships(user = c("JennyBryan", "hadleywickham"))Data Collection — lists_members
Collect data on users listed in one list
- specify the list with the
list_idargument- e.g., with data from
lists_memberships
- e.g., with data from
- or the
owner_userandslugarguments together - limited to 5,000 members
- specify the list with the
Note that
- lists also appear at twitter.com/USERNAME/lists
- see, for example, twitter.com/TwitterGov/lists
lists_members(list_id = NULL, slug = NULL, owner_user = NULL, n = 5000, cursor = "-1", token = NULL, parse = TRUE, ...)Data Collection — lists_members
Collect data on the list of MPs in the House of Commons
- using the
list_idargument
lists_members(list_id = "217199644")Data Collection — lists_members
Collect data on the list of MPs in the House of Commons
- using the
list_idargument
lists_members(list_id = "217199644")Collect the same data, with different arguments
- using the
owner_userandslugarguments
lists_members(owner_user = "TwitterGov", slug = "UK-MPs")Data Collection — lists_statuses
Collect tweets from the timeline of a list
- i.e., tweets posted by those listed on a given list
- specify the list with the
list_idargument - or the
owner_userandslugarguments together
lists_statuses(list_id = NULL, slug = NULL, owner_user = NULL, since_id = NULL, max_id = NULL, n = 200, include_rts = TRUE, parse = TRUE, token = NULL)Data Collection — lists_statuses
Collect tweets posted by the members of the UK MPs list
- using the
list_idargument
lists_statuses(list_id = "217199644")Data Collection — lists_statuses
Collect tweets posted by the members of the UK MPs list
- using the
list_idargument
lists_statuses(list_id = "217199644")Collect the same data, with different arguments
- using the
owner_userandslugarguments
lists_statuses(owner_user = "TwitterGov", slug = "UK-MPs")Data Collection — lists_subscribers
Collect data on users subscribed to a given list
- i.e., users who are following a list
- specify the list with the
list_idargument - or with the
owner_userandslugarguments - limited to 5,000 users
lists_subscribers(list_id = NULL, slug = NULL, owner_user = NULL, n = 20, cursor = "-1", parse = TRUE, token = NULL)Data Collection — lists_subscribers
Collect data on users subscribed to the UKMPs list
- using the
list_idargument
lists_subscribers(list_id = "1405362")Data Collection — lists_subscribers
Collect data on users subscribed to the UKMPs list
- using the
list_idargument
lists_subscribers(list_id = "1405362")Collect the same data, with different arguments
- using the
owner_userandslugarguments
lists_subscribers(owner_user = "TwitterGov", slug = "UK-MPs")Data Collection — lists_subscriptions
Collect data on the lists a user is subscribed to
- specify the user with
userargument- takes user ID or username
- limited to 1,000 subscriptions
lists_subscriptions(user, n = 20, cursor = "-1", parse = TRUE, token = NULL)Data Collection — lists_subscriptions
Collect data on the lists that TwitterGov is subscribed to
lists_subscriptions(user = "TwitterGov")Exercises
31) Collect data on lists where Hadley Wickham is listed
- hint: Wickham's username is "hadleywickham"
32) For one of these lists, see who else is listed with Hadley Wickham
- compare and contrast this data with what you can see on a browser
33) Collect the latest posts from that list
34) Collect data on users subscribed to that list
35) For one of these users, see if they are subscribed to any other lists
10:00
stream_tweets
Data Collection — stream_tweets
Collect tweets as they are posted real time
- about 1% of all new public Tweets, randomly chosen
- set the length of search with the
timeoutargument
The search can be limited with the
qargument- up to 400 keywords
- up to 5,000 user IDs or usernames
- location coordinates of geographical boxes
- not two, but four coordinates
Note that
- this function uses the stream APIs
- unlike any other function covered so far
stream_tweets(q = "", timeout = 30, parse = TRUE, token = NULL, file_name = NULL, verbose = TRUE, ...)Data Collection — stream_tweets
Collect a random sample of tweets being sent
- continuously
Note that
- the
timeoutfunction can be set to infinity - you are likely to run into connection problems at some point
- the
stream_tweets(q = "", timeout = Inf)Data Collection — stream_tweets
Collect a random sample of tweets being sent
- for 30 seconds
Note that
timeoutvalues are otherwise in seconds
stream_tweets(q = "", timeout = 30)Data Collection — stream_tweets
Collect a random sample of tweets being sent
- for 30 seconds
- filtered by a search query
Note that
qaccepts a comma separated character string
stream_tweets(q = "switzerland, schweiz, suisse, svizzera", timeout = 30)Data Collection — stream_tweets
Collect a random sample of tweets being sent
- for 30 seconds
- filtered by usernames
Note that
qaccepts a comma separated list
stream_tweets(q = c("UniLuzern", "hslu", "phluzern"), timeout = 30)Data Collection — stream_tweets
Collect a random sample of tweets being sent
- for 30 seconds
- filtered by coordinates
stream_tweets(q = c(6.02, 45.77, 10.44, 47.83), timeout = 30)Exercises
36) Stream for all tweets, for 30 seconds
- observer the outcome, and compare them with the outcomes from below
37) Further limit your stream by a popular keyword
- e.g., "and"
- stream for 30 more seconds
38) Further limit your stream to a not so popular word
- e.g., "PhD"
- stream for 30 more seconds
39) Stream for a word or words that interest you
10:00
Data Preperation — Overview
The
rtweetpackage does a very good job with data preperation to start with- returns data frames, with mostly tidy data
- although Twitter APIs return nested lists
- some variables are still lists
- e.g.,
hastags
- e.g.,
Data Preperation — Overview
The
rtweetpackage does a very good job with data preperation to start with- returns data frames, with mostly tidy data
- although Twitter APIs return nested lists
- some variables are still lists
- e.g.,
hastags
- e.g.,
Further data preparation depends on your research project
- most importantly, on whether you will work with texts or not
- we will cover some common preparation steps
Data Preperation — Overview — Strings
Most researchers would be interested in textual Twitter data
- tweets as a whole, but also specifically hashtags etc.
Data Preperation — Overview — Strings
Most researchers would be interested in textual Twitter data
- tweets as a whole, but also specifically hashtags etc.
There are many components of tweets as texts
- e.g., mentions, hashtags, emojis, links etc.
- but also punctuation, white spaces, upper case letters etc.
- some of these may need to be taken out before analysis
Data Preperation — Overview — Strings
Most researchers would be interested in textual Twitter data
- tweets as a whole, but also specifically hashtags etc.
There are many components of tweets as texts
- e.g., mentions, hashtags, emojis, links etc.
- but also punctuation, white spaces, upper case letters etc.
- some of these may need to be taken out before analysis
I use the
stringrpackage (Wickham, 2019) for string operations- part of the
tidyversefamily - you might have another favourite already
- no need to change as long as it does the job
- part of the
Data Preperation — Overview — Numbers
There is more to Twitter data than just tweets themselves
- e.g., the number of followers, likes etc.
- see Silva and Proksch (Silva and Proksch, 2021) for a great study on numbers
- e.g., the number of followers, likes etc.
Data Preperation — Overview — Numbers
There is more to Twitter data than just tweets themselves
- e.g., the number of followers, likes etc.
- see Silva and Proksch (Silva and Proksch, 2021) for a great study on numbers
- e.g., the number of followers, likes etc.
I use the
dplyrpackage (Wickham, François, Henry, and Müller, 2022) for most data operations on numbers- part of the
tidyversefamily - you might have another favourite already
- no need to change as long as it does the job
- part of the
Data Preperation — Remove Mentions
tweet <- "These from @handle1 are #socool. 👏 A #mustsee, @handle2! 👉 https://t.co/aq7MJJ2"str_remove_all(string = tweet, pattern = "[@][\\w_-]+")[1] "This from are #socool. 👏 A #mustsee, ! 👉 https://t.co/aq7MJJ2"
Note that
- this removes all occurrences
- there is also the
str_removefucntion, which removes the first occurrence only
Data Preperation — Remove Hashtags
tweet <- "These from @handle1 are #socool. 👏 A #mustsee, @handle2! 👉 https://t.co/aq7MJJ2"str_remove_all(string = tweet, pattern = "[#][\\w_-]+")[1] "These from @handle1 are . 👏 A , @handle2! 👉 https://t.co/aq7MJJ2"
Data Preperation — Exercises — Notes
The exercises in this part are best followed by
- using
tweets.rdsor a similar existing dataset - saving a new variable at every step of preparation
- observing the newly created variables
- by selecting only the old and new variable
- to confirm whether the code works as intended
- using
- The
mutateandselectfunctions, from thedplyrpackage, can be helpful, as follows
df_tweets <- read_rds("data/tweets.rds")df_tweets %>% mutate(no_mentions = str_remove_all(string = text, pattern = "[@][\\w_-]+")) %>% select(text, no_mentions) %>% View()Exercises
40) Create a new variable without mentions
41) Create a new variable without hashtags
05:00
Data Preperation — Remove Links
tweet <- "These from @handle1 are #socool. 👏 A #mustsee, @handle2! 👉 https://t.co/aq7MJJ2"str_remove_all(string = tweet, pattern = "http\\S+\\s*")[1] "These from @handle1 are. 👏 A, @handle2! 👉 "
Data Preperation — Remove Emojis
tweet <- "These from @handle1 are #socool. 👏 A #mustsee, @handle2! 👉 https://t.co/aq7MJJ2"iconv(x = tweet, from = "latin1", to = "ASCII", sub = "")[1] "These from @handle1 are #socool. A #mustsee, @handle2! https://t.co/aq7MJJ2"
Exercises
42) Create a new variable without links
43) Create a new variable without emojis
44) Create a new variable without:
- mentions, hashtags, links, and emojis
10:00
Data Preperation — Remove Punctuations
tweet <- "These from @handle1 are #socool. 👏 A #mustsee, @handle2! 👉 https://t.co/aq7MJJ2"str_remove_all(string = tweet, pattern = "[[:punct:]]")[1] "This from are socool 👏 A mustsee handle2 👉 httpstcoaq7MJJ2"
Note that
- this removed all punctuation, including those in links
Data Preperation — Remove Punctuations
tweet <- "This is a sentence.There is no space before this sentence."str_remove_all(string = tweet, pattern = "[[:punct:]]")[1] "This is a sentenceThere is no space before this sentence"
Note that
- if tweets are typed with no spaces after punctuation, this might lead to merged pieces of text
- alternatively, try the
str_replace_allfunction to replace punctuation with space
- alternatively, try the
Data Preperation — Replace Punctuations
tweet <- "This is a sentence.There is no space before this sentence."str_replace_all(string = tweet, pattern = "[[:punct:]]", replacement = " ")[1] "This is a sentence There is no space before this sentence "
Data Preperation — Remove Repeated Whitespace
tweet <- "There are too many spaces after this sentence. This is a new sentence."str_squish(string = tweet)[1] "There are too many spaces after this sentence. This is a new sentence."
Note that
- white spaces can be introduced not only by users on Twitter, but also by us, while cleaning the data
- e.g., removing and/or replacing operations above
- hence, this function might be useful after other operations
Data Preperation — Change Case
tweet <- "lower case. Sentence case. Title Case. UPPER CASE."str_to_lower(string = tweet)[1] "lower case. sentence case. title case. upper case."
Note that
- there are other functions in this family, including
str_to_sentence,str_to_title,str_to_upper
Exercises
45) Remove punctuation
46) Remove repeated whitespace
47) Change case to lower case
10:00
Data Preperation — Change Unit of Observation
Research designs might require changing the unit of observation
- aggregation
- e.g., at the level of users, locations, hashtags etc.
- summarise with
dplyr
- dis-aggregation
- e.g., to the level of words
- tokenise with
tidytext
Data Preperation — Change Unit of Observation — Aggregation
Aggregate at the level of users
- the number of tweets per user
# load the tweets datasetdf <- read_rds("tweets.rds") %>%# group by users for aggregation group_by(user_id) %>%# create summary statistics for variables of interest summarise(sum_tweets = n())Data Preperation — Change Unit of Observation — Aggregation
What is aggregated at which level depends on your research design, such as
- aggregate the tweets into a single text
- at the level of users by source
# load the tweets datasetdf <- read_rds("tweets.rds") %>%# group by users for aggregation group_by(user_id, source) %>%# create summary statistics for variables of interest summarise(merged_tweets = paste0(text, collapse = ". "))Data Preperation — Change Unit of Observation — Dis-aggregation
Disaggregate the tweets, by splitting them into smaller units
- also called tokenisation
Note that
- by default
sep = "[^[:alnum:].]+", which works well with separating tweets into words- change this argument with a regular expression of your choice
- this creates a tidy dataset, where each observation is a word
- all other tweet-level variables are repeated for each observation
# load the tweets datasetdf <- read_rds("tweets.rds") %>%# split the variable text separate_rows(text)Data Preperation — Change Unit of Observation — Dis-aggregation
The tidytext has a function that works better with tokenising tweets
- with
token = "tweets", it dis-aggregates text into words- except that it respects usernames, hashtags, and URLS
# load the tweets datasetdf <- read_rds("tweets.rds") %>%# split the variable text, create a new variable called da_tweets unnest_tokens(output = da_tweets, input = text, token = "tweets")Data Preperation — Change Unit of Observation — Dis-aggregation
Tokenise variables to levels other than words
- e.g., characters, words (the default), sentences, lines
# load the tweets datasetdf <- read_rds("tweets.rds") %>%# split the variable text into sentences, create a new variable called da_tweets unnest_tokens(output = da_tweets, input = text, token = "sentences")Data Preperation — Change Unit of Observation — Dis-aggregation
Tokenise variables other than tweets
- recall that
rtweetstores multiple hastags, mentions etc. as lists
# load the tweets datasetdf <- read_rds("tweets.rds") %>%# unlist the lists of hashtags to create strings group_by(status_id) %>% mutate(tidy_hashtags = str_c(unlist(hashtags), collapse = " ")) %>%# split the string, create a new variable called da_tweets unnest_tokens(output = da_hashtags, input = tidy_hashtags, token = "words")Data Preperation — Remove Stop Words
Remove the common, uninformative words
- e.g., the, a, i
Note that
- this operation requires a tokenised-to-word variable
- stop words for English are stored in the
stop_wordsdataset in thetidytextvariable - list of words for other languages are available elsewhere, including
- the
stopwordslangsfunction from thertweetpackage - the
stopwordsfunction from thetmpackage- e.g., use
tm::stopwords("german")for German
- e.g., use
- the
# load the tweets datasetdf <- read_rds("tweets.rds") %>%# split the variable text, create a new variable called da_tweets unnest_tokens(output = da_tweets, input = text, token = "tweets") %>%# remove rows that match any of the stop words as stored in the stop_words dataset anti_join(stop_words, by = c("da_tweets" = "word"))Exercises
48) Aggregate text to a higher level
- e.g., if you are using
tweets.rds, to MP level -and add at least two numerical variables- e.g., average number of likes
49) Dis-aggregate text to a lower level
- e.g., to words
50) Dis-aggregate hashtags
- as one tweet can include multiple hashtags
51) Remove stop words
15:00
Analysing Users — Overview
Twitter analysis might focus on users
- e.g., members of parliaments
- as opposed to their tweets on Twitter
- not always mutually exclusive
- not always mutually exclusive
- might be supplemented with non-Twitter data
- e.g.,
data/mps.csv
- e.g.,
Analysing Users — Overview
Twitter analysis might focus on users
- e.g., members of parliaments
- as opposed to their tweets on Twitter
- not always mutually exclusive
- not always mutually exclusive
- might be supplemented with non-Twitter data
- e.g.,
data/mps.csv
- e.g.,
There are at least two types of user-based analysis
- count things, and describe or correlate
- e.g., who has the most followers
- are female MPs more or less likely to have large number of followers?
- are female MPs more or less likely to have large number of followers?
- e.g., who has the most followers
- network analysis
- e.g., who retweets whom, how often?
- count things, and describe or correlate
Analysing Users — Correlates of being on Twitter
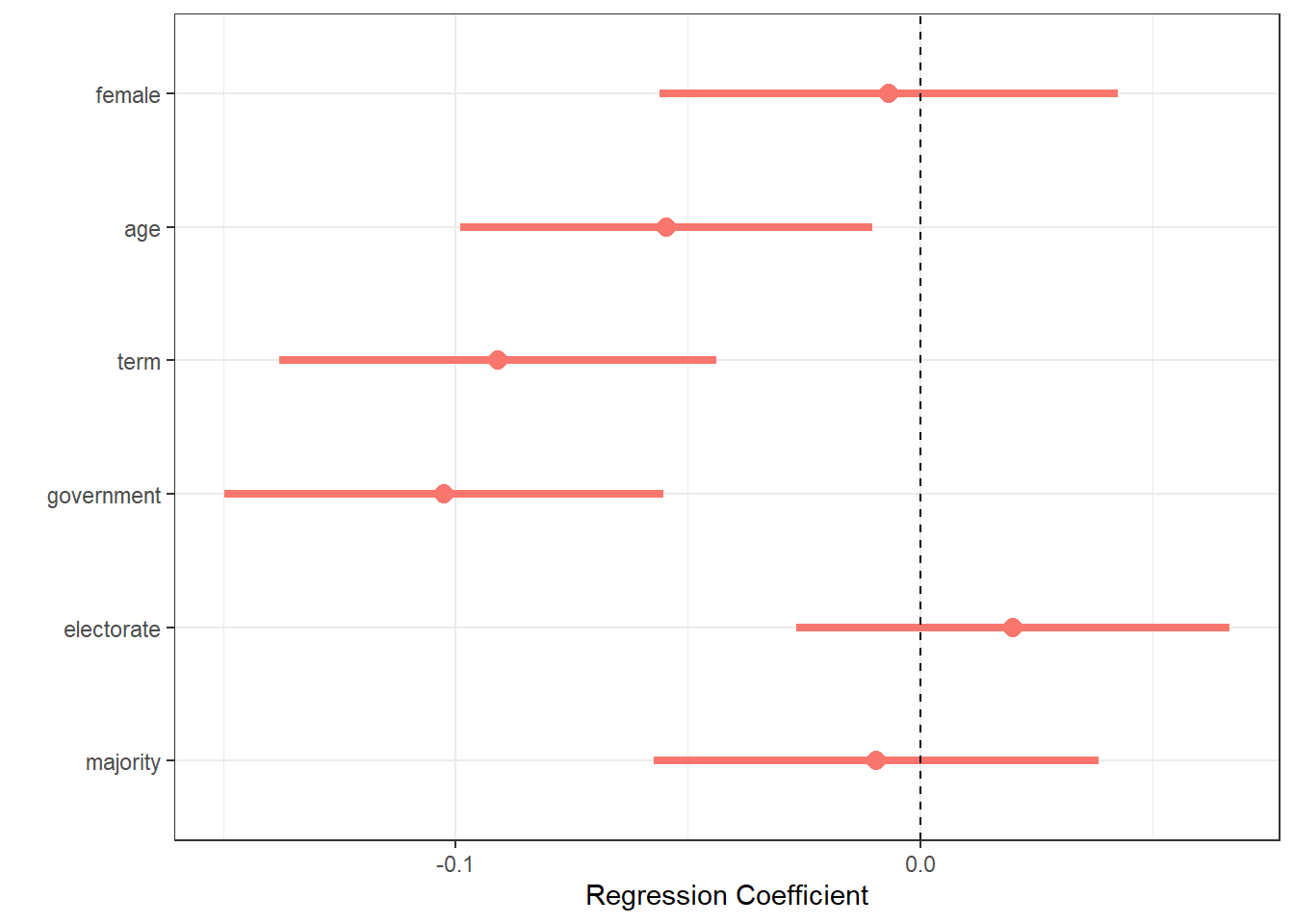
Analysing Users — Who has the most followers?
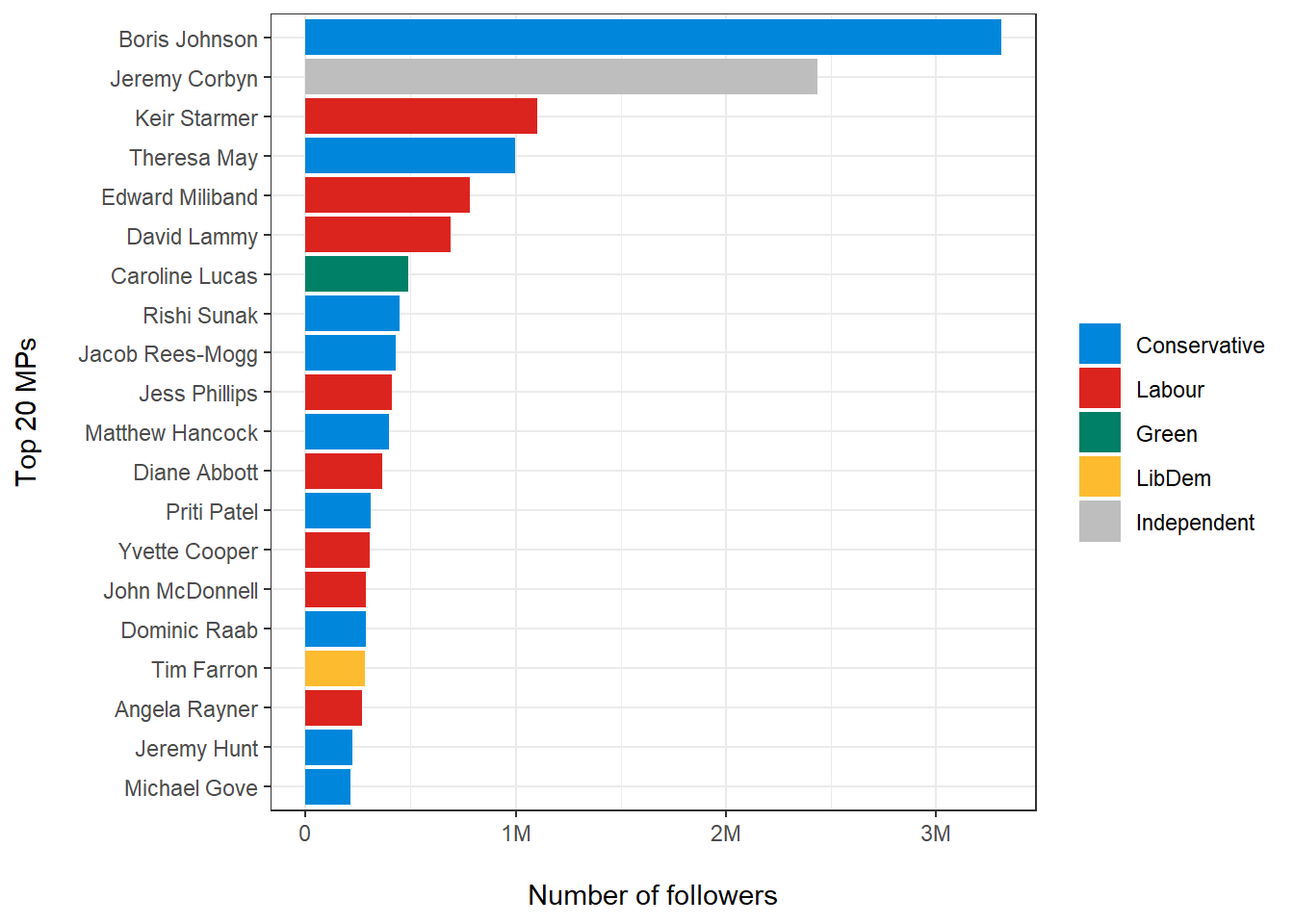
Exercises
On users.Rmd, complete the following exercises
52) Correlates of being on Twitter
53) Who has the most followers?
20:00
Analysing Users — Correlates of having more followers
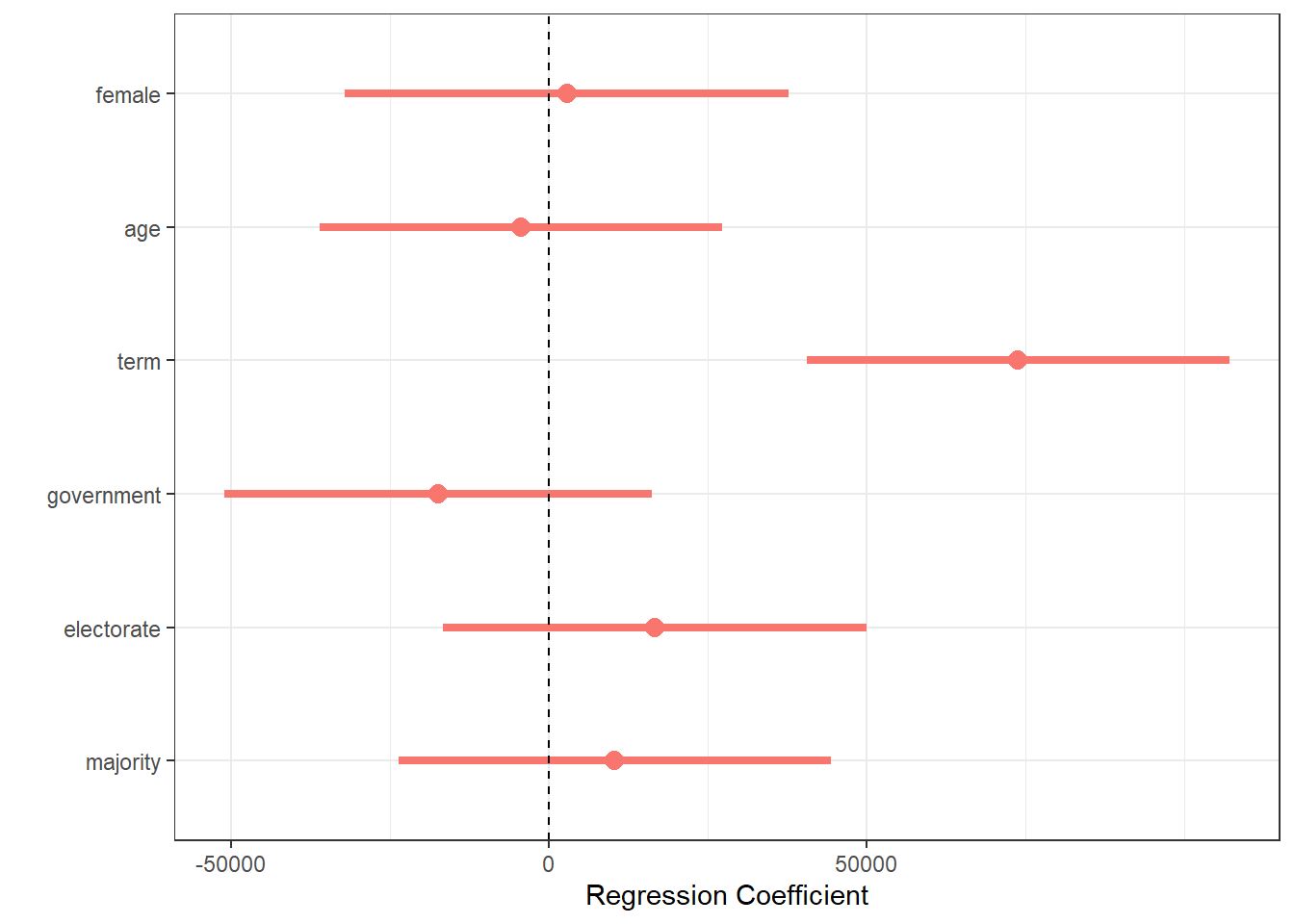
Analysing Users — Who tweets the most often?
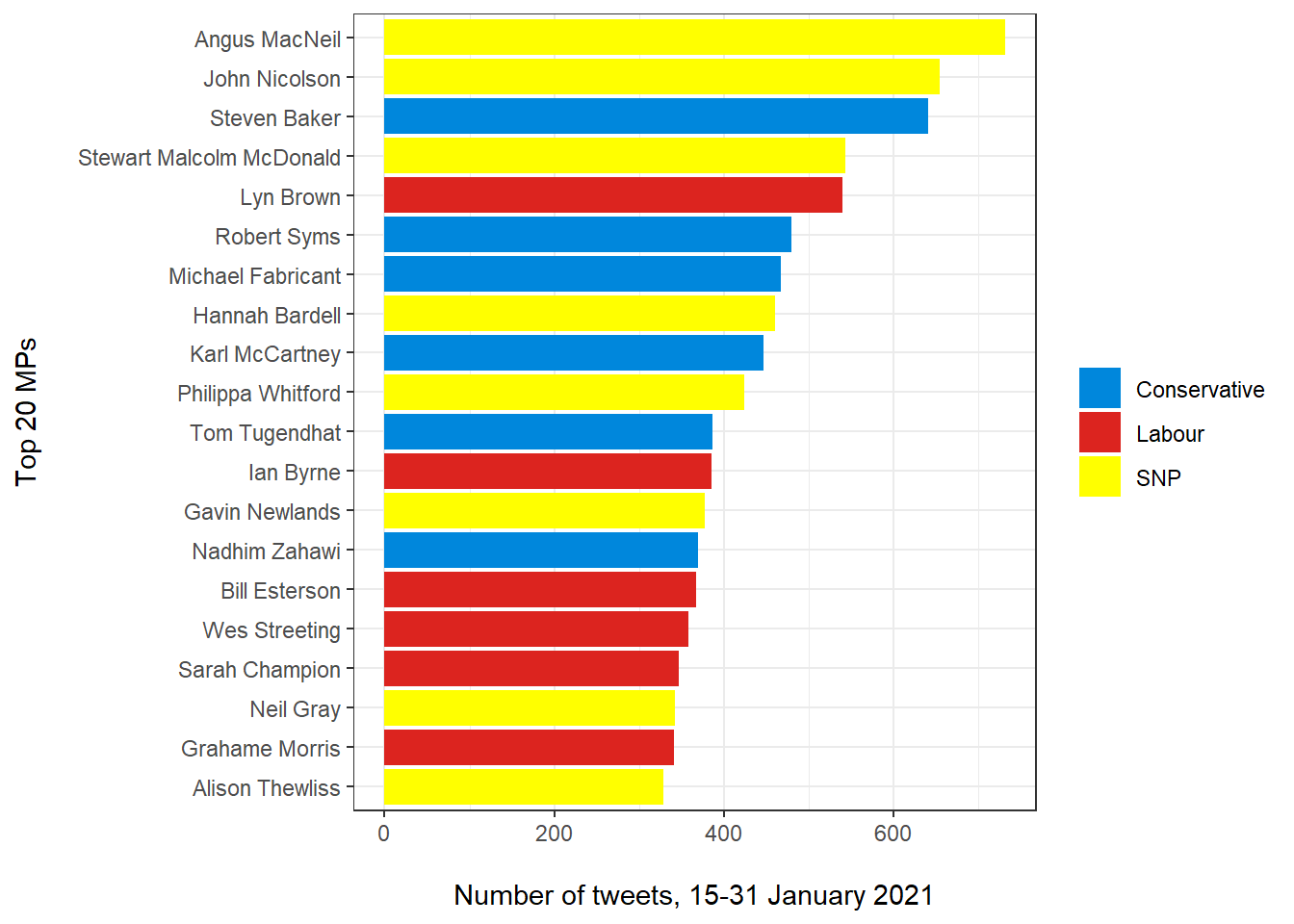
Exercises
On users.Rmd, complete the following exercises
54) Correlates of having more followers
55) Who tweets the most often?
20:00
Analysing Users — Correlates of tweeting more often
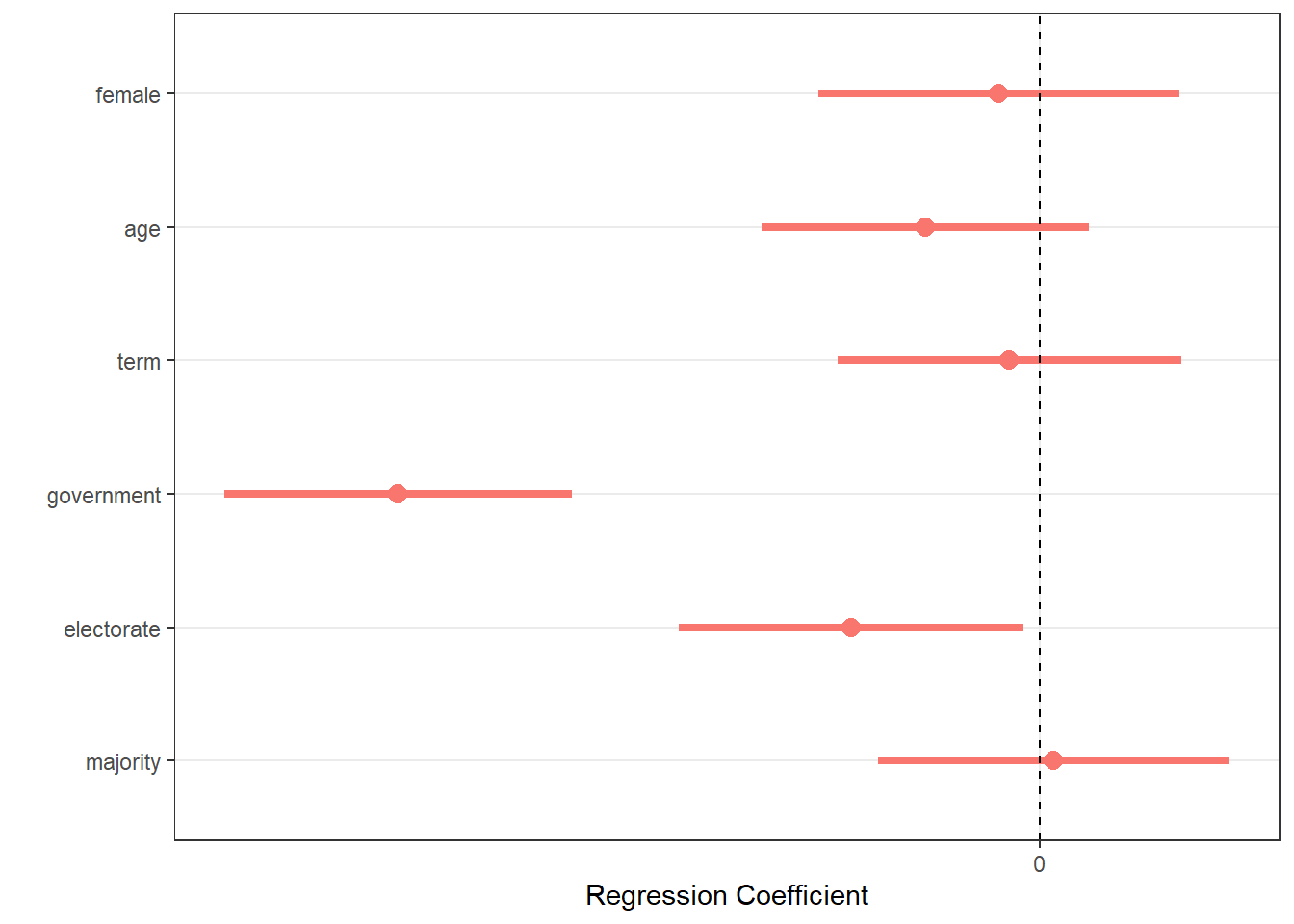
Analysing Users — Who do they talk to?
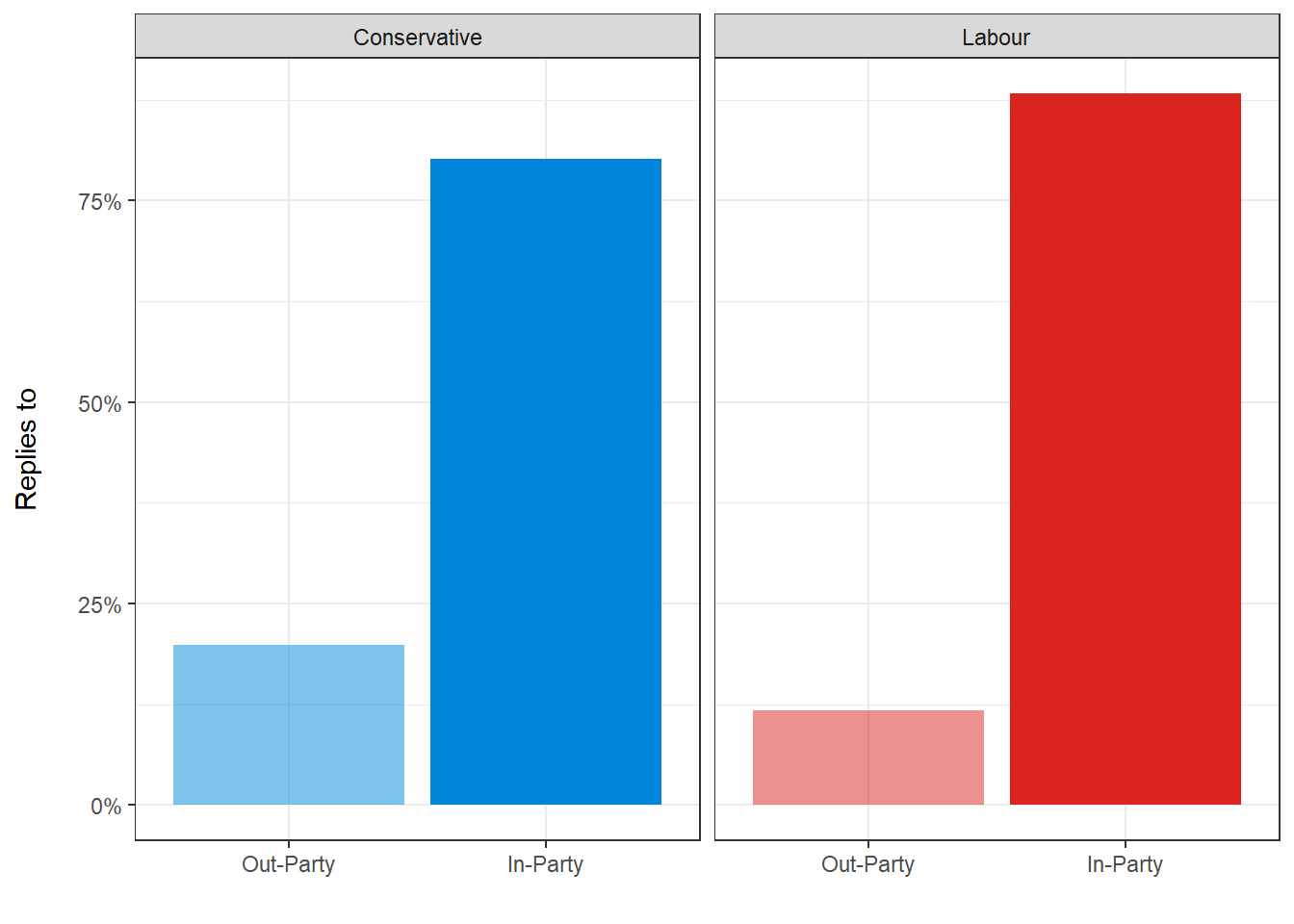
Exercises
On users.Rmd, complete the following exercises
56) Correlates of tweeting more often
57) Who do they talk to?
20:00
Network Analysis
Analysing Users — Network Analysis — Overview
Twitter data is suitable for network analysis
- a social network
- studying the relations between users
There are at least five networks
- networks of followers
- directed, not reoccurring
- e.g., who is following whom
- networks of retweeters, quoters, repliers, and likers
- directed, reoccurring
- e.g., who is replying to whom, how often
- networks of followers
Analysing Users — Network Analysis — Basics
Networks are composed of nodes and edges
- e.g., who (a node) replies (an edge) to whom (another node), how often (the strength of the edge)
Analysing Users — Network Analysis — Basics
Networks are composed of nodes and edges
- e.g., who (a node) replies (an edge) to whom (another node), how often (the strength of the edge)
The nodes and edges are often kept separate for analysis
- e.g., in separate datasets, frames
- nodes are given an ID number
Analysing Users — Network Analysis — Basics
Networks are composed of nodes and edges
- e.g., who (a node) replies (an edge) to whom (another node), how often (the strength of the edge)
The nodes and edges are often kept separate for analysis
- e.g., in separate datasets, frames
- nodes are given an ID number
We will use two pacakges for network analysis
tidygraphfor data manipulationggraphfor visualisation
Analysing Users — Network Analysis — tidygraph
read_rds("data/tweets.rds") %>% filter(is_retweet == TRUE) %>% group_by(screen_name, retweet_screen_name) %>% summarise(rts = n()) %>% head()# A tibble: 6 x 3 # Groups: screen_name [1] screen_name retweet_screen_name rts1 _OliviaBlake AlexDaviesJones 1 2 _OliviaBlake CommonsPAC 2 3 _OliviaBlake DanJarvisMP 3 4 _OliviaBlake DrRosena 1 5 _OliviaBlake EmmaHardyMP 1 6 _OliviaBlake FriendsLoxley 2
Analysing Users — Network Analysis — tidygraph
Use the as_tbl_graph function to transform data frames
read_rds("data/tweets.rds") %>% filter(is_retweet == TRUE) %>% group_by(screen_name, retweet_screen_name) %>% summarise(rts = n()) %>% as_tbl_graph()# A tbl_graph: 7377 nodes and 16131 edges # # A directed multigraph with 5 components # # Node Data: 7,377 x 1 (active) name1 _OliviaBlake 2 _RobbieMoore 3 AaronBell4NUL 4 ab4scambs 5 abenaopp 6 ABridgen # ... with 7,371 more rows # # Edge Data: 16,131 x 3 from to rts 1 1 19 1 2 1 550 2 3 1 119 3 # ... with 16,128 more rows
Analysing Users — Network Analysis — tidygraph
Use the activate function to manipulate the nodes or edges
read_rds("data/tweets.rds") %>% filter(is_retweet == TRUE) %>% group_by(screen_name, retweet_screen_name) %>% summarise(rts = n()) %>% as_tbl_graph() %>% activate(edges) %>% mutate(multi_rts = if_else(rts > 1, 1, 0))# A tbl_graph: 7377 nodes and 16131 edges # # A directed multigraph with 5 components # # Edge Data: 16,131 x 4 (active) from to rts multi_rts1 1 19 1 0 2 1 550 2 1 3 1 119 3 1 4 1 154 1 0 5 1 167 1 0 6 1 551 2 1 # ... with 16,125 more rows # # Node Data: 7,377 x 1 name 1 _OliviaBlake 2 _RobbieMoore 3 AaronBell4NUL # ... with 7,374 more rows
Analysing Users — Network Analysis — ggraph
Once the nodes and edges are ready, use the ggraph package to visualise
- an extension of
ggplot2 - many verbs are intuitively similar
ggraph(rt_network) + geom_edge_link() + geom_node_point(aes(color = party)) + theme_graph()Analysing Users — Reply networks
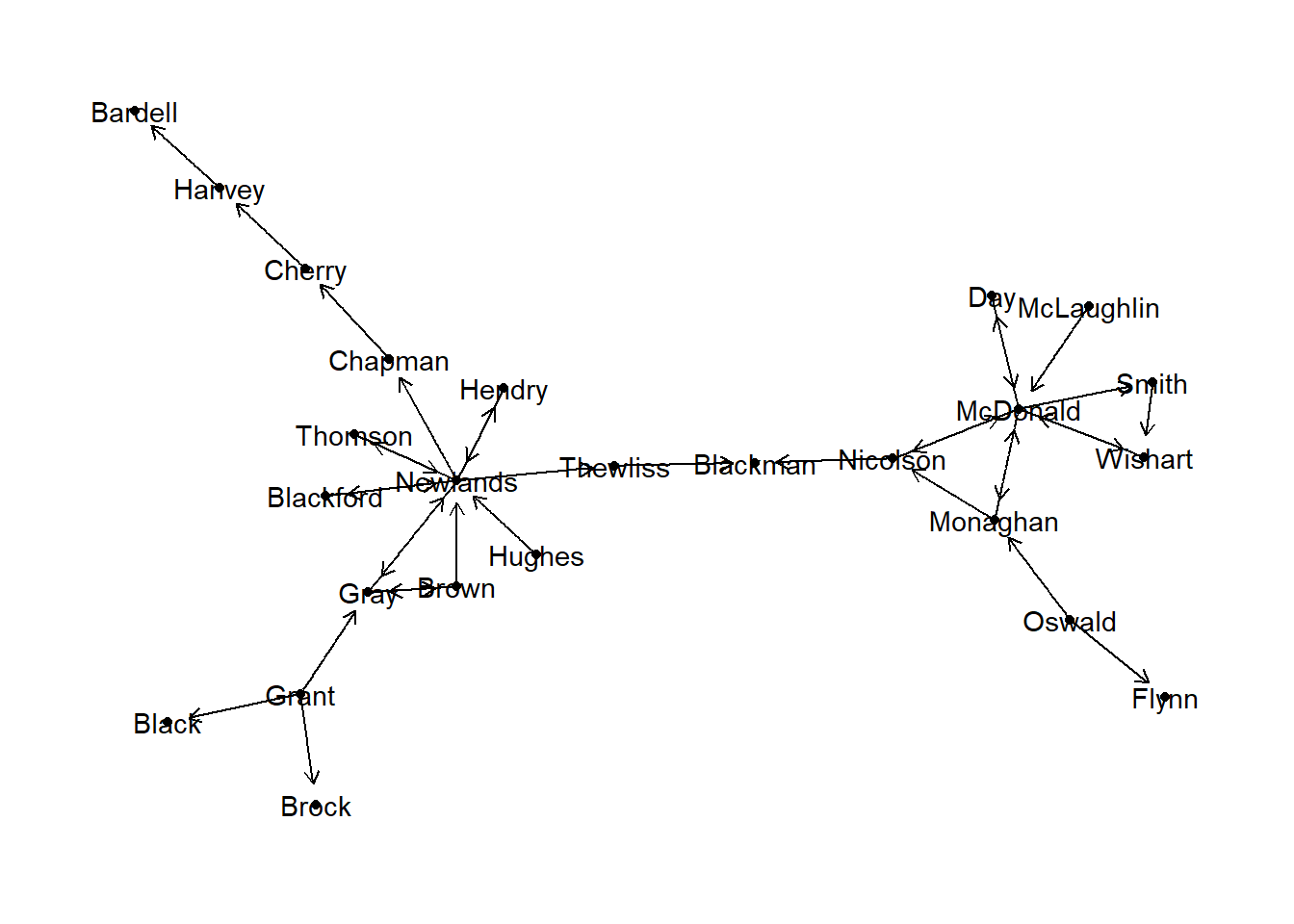
Analysing Users — Retweet networks
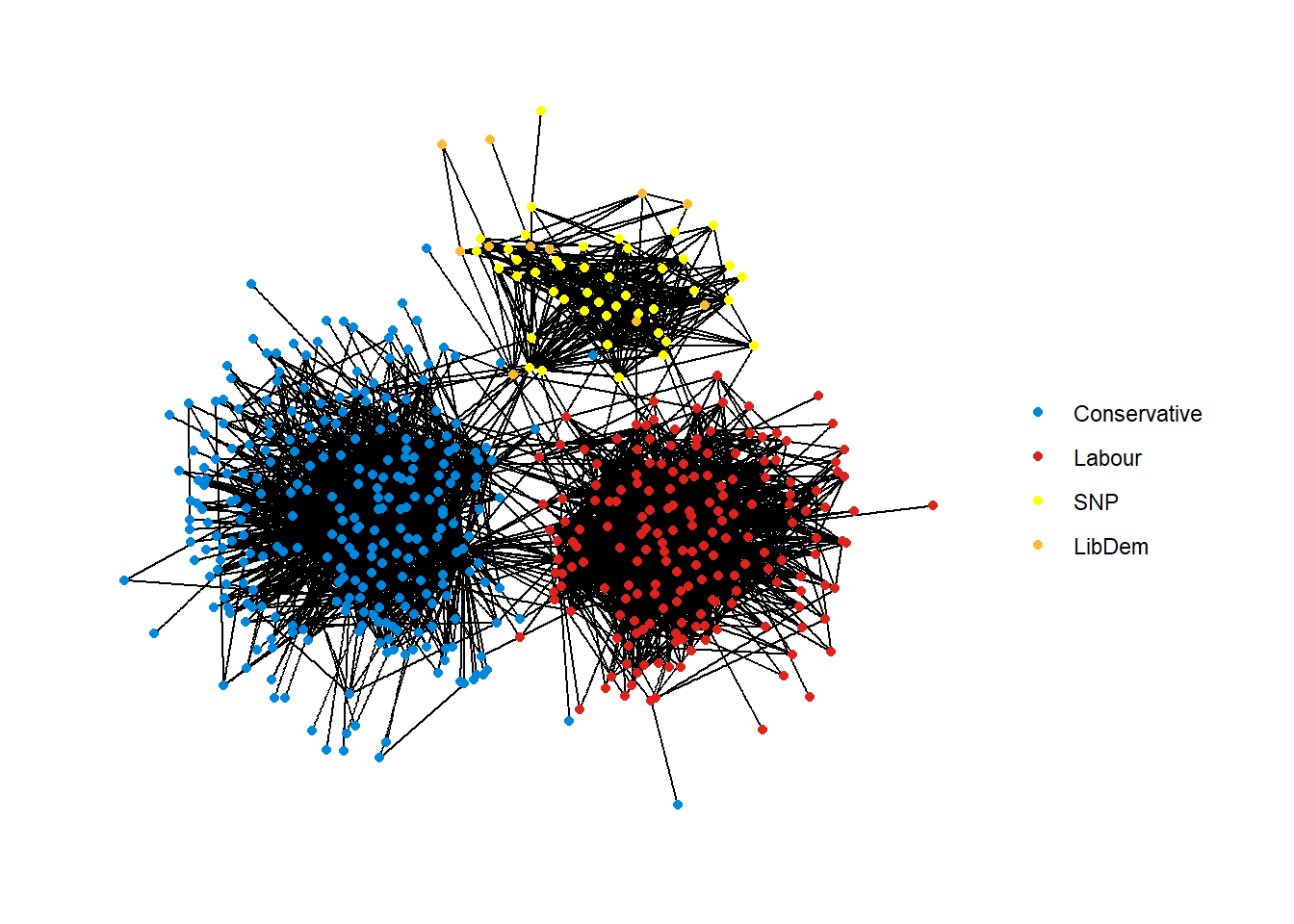
Exercises
On users.Rmd, complete the following exercises
58) Reply networks
59) Retweet networks
20:00
Analysing Users — Who are more central in the retweet networks?
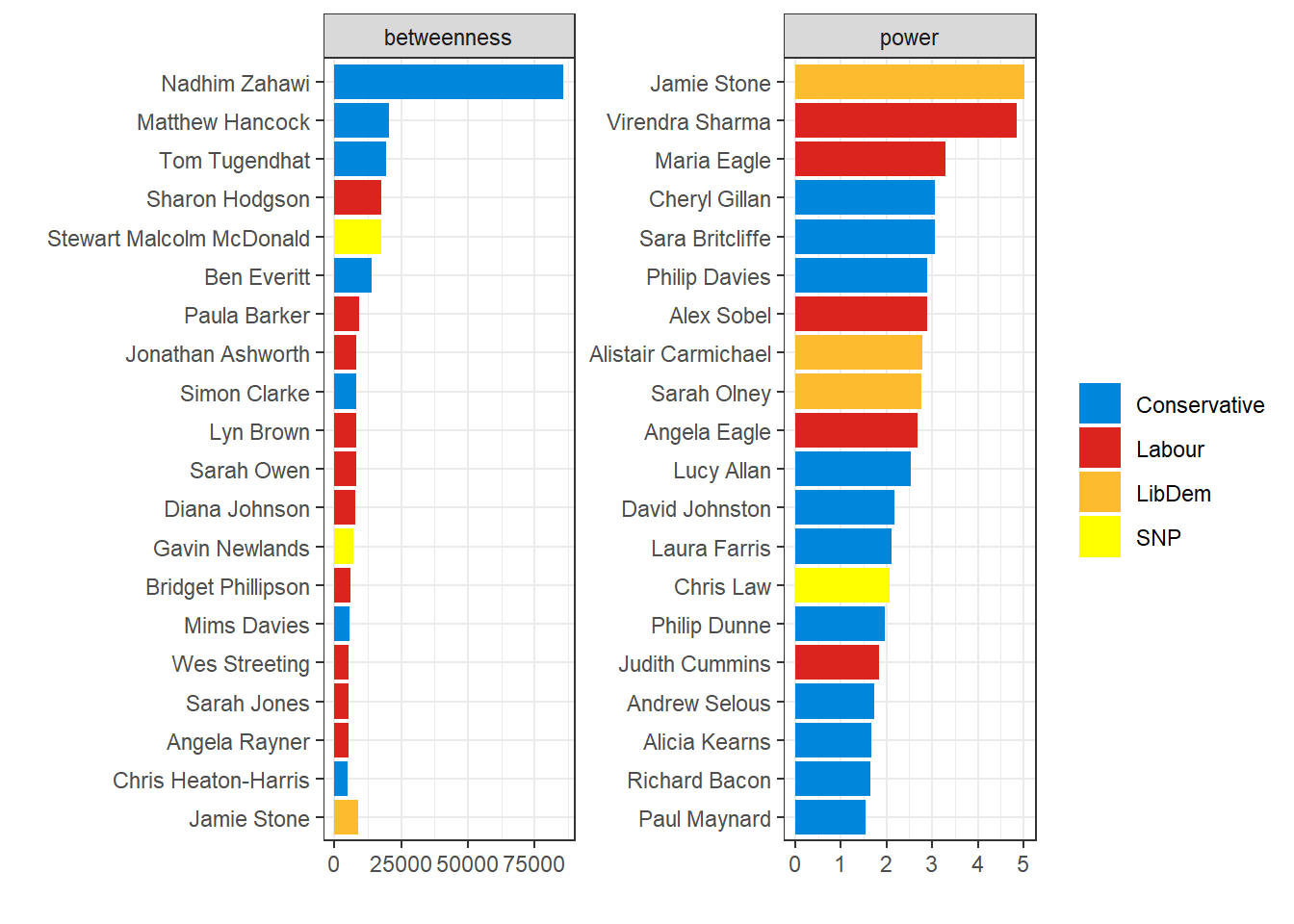
Exercises
On users.Rmd, complete the following exercises
60) Who are more central in the retweet networks?
61) Something else interesting about MPs
63) Something interesting from your own data
45:00
Analysing Tweets — Overview
Twitter analysis often focuses on tweets
- e.g., text in the tweets, but also hashtags
- as opposed to users who tweet them
- not always mutually exclusive
- hard to supplement ordinary users with non-Twitter data
Analysing Tweets — Overview
Twitter analysis often focuses on tweets
- e.g., text in the tweets, but also hashtags
- as opposed to users who tweet them
- not always mutually exclusive
- hard to supplement ordinary users with non-Twitter data
There are at least two types of tweet-based analysis
- count things, and describe or correlate
- e.g., how often a hashtag is tweeted
- are shorter hashtags more likely to be tweeted than longer ones?
- e.g., how often a hashtag is tweeted
- categorising tweets
- e.g., with dictionaries
- but also with other techniques such as machiene learning
- e.g., with dictionaries
- count things, and describe or correlate
Analysing Tweets — When were the tweets posted?
Analysing Tweets — What day of the week?
Analysing Tweets — What time of the day?
Exercises
On tweets.Rmd, complete the following exercises
63) When were the tweets posted?
64) What day of the week?
65) What time of the day?
20:00
Analysing Tweets — Which hastags were the most frequent?
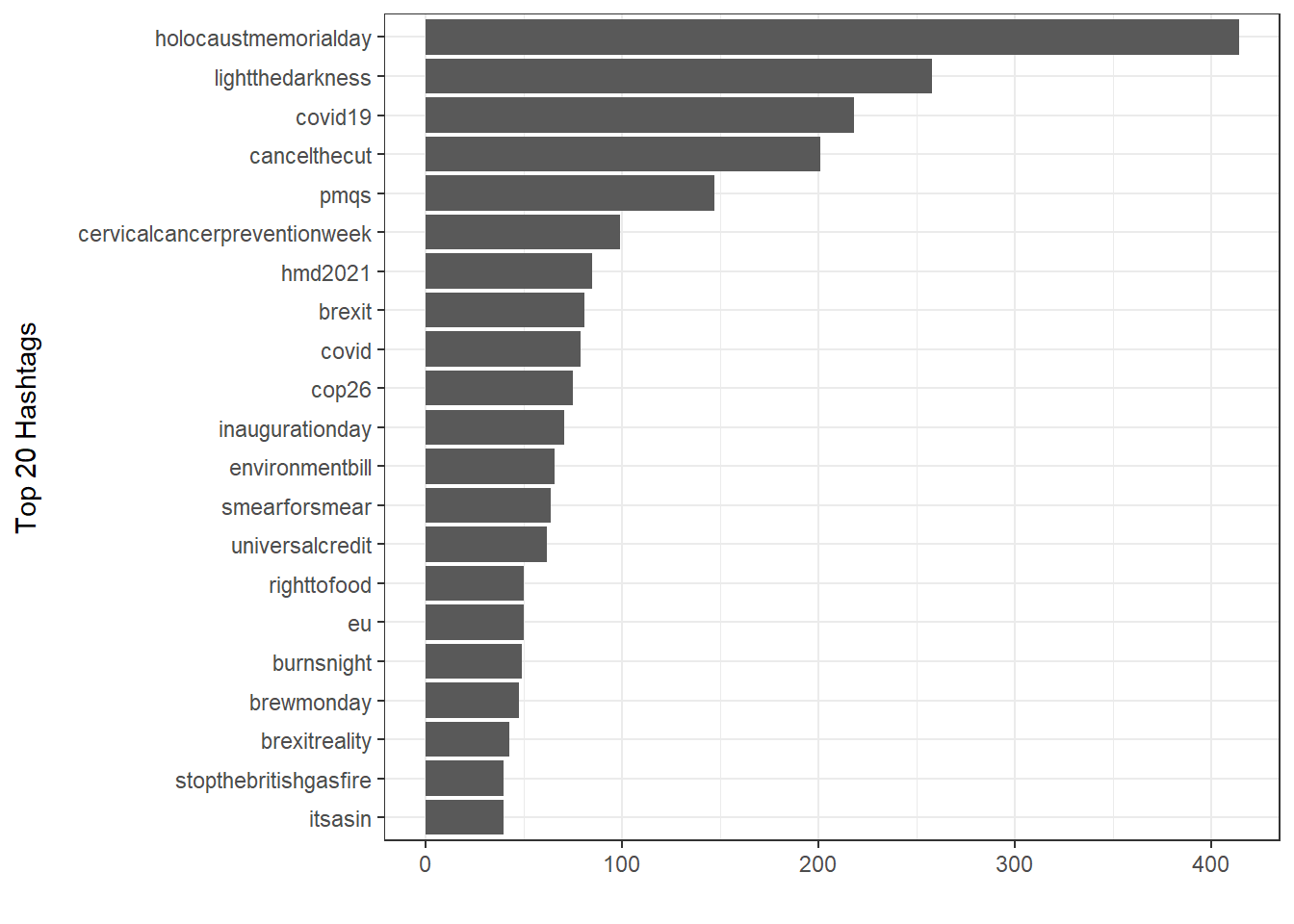
Analysing Tweets — Which words were the most frequent?

Exercises
On tweets.Rmd, complete the following exercises
66) Which hastags were the most frequent?
67) Which words were the most frequent?
20:00
Dictionary Methods
Analysing Users — Dictionary Methods — Overview
Dictionary methods are based on pre-categorisation of words
e.g., the word happy might be categorised as positive
- sad would be negative
e.g., the word happy might be categorised as 0.2 sophisticated
- contented might be 0.4 sophisticated
Analysing Users — Dictionary Methods — Overview
Dictionary methods are based on pre-categorisation of words
e.g., the word happy might be categorised as positive
- sad would be negative
e.g., the word happy might be categorised as 0.2 sophisticated
- contented might be 0.4 sophisticated
These catagories are than matched with the text we have
- to calculate scores for, e.g., each tweet
Analysing Users — Dictionary Methods — Notes
There are many ways to calculate scores
- depending on your research design
Positive score could be
sum(positive)sum(positive) - sum(negative)(sum(positive) - sum(negative)) / (sum(positive) + sum(negative))
We will use
- the sentiment dictionary stored at
tidytext::get_sentiments("nrc") - the concreteness dictionary stored at
doc2concrete::mturk_list
- the sentiment dictionary stored at
Analysing Tweets — Sentiments by Hours of the Day
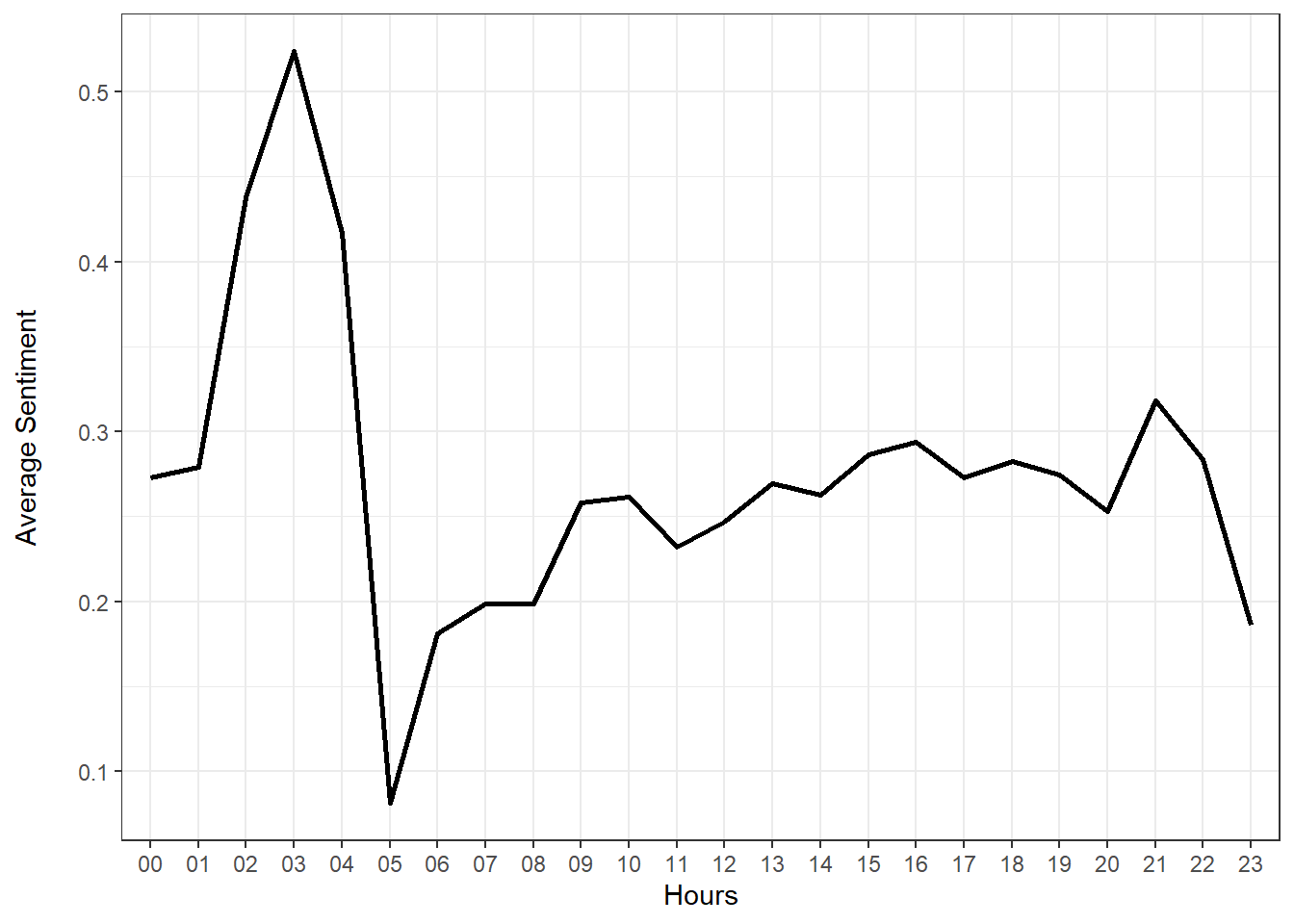
Analysing Tweets — Sentiments across the time frame
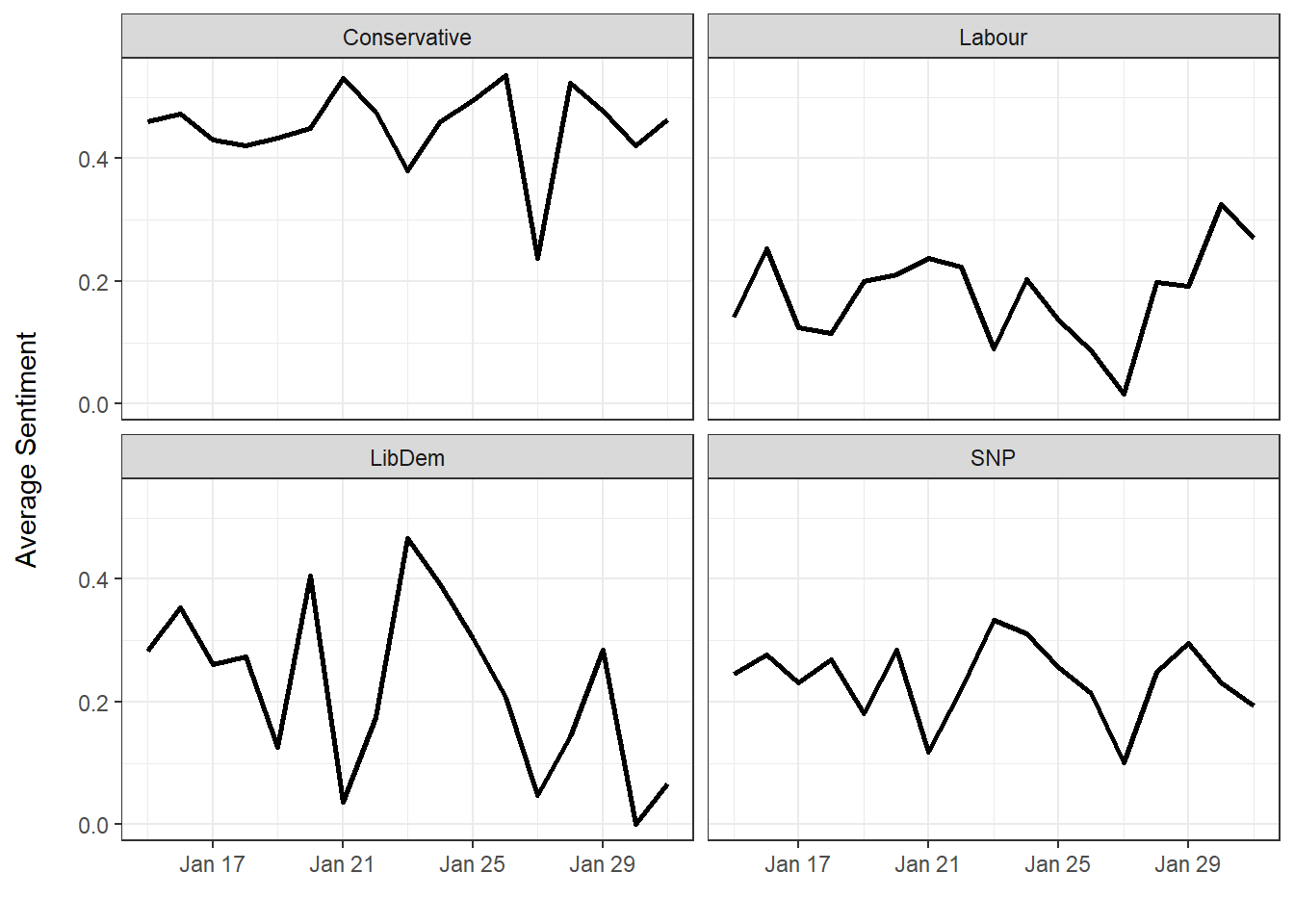
Analysing Tweets — Sentiments in different types of tweets
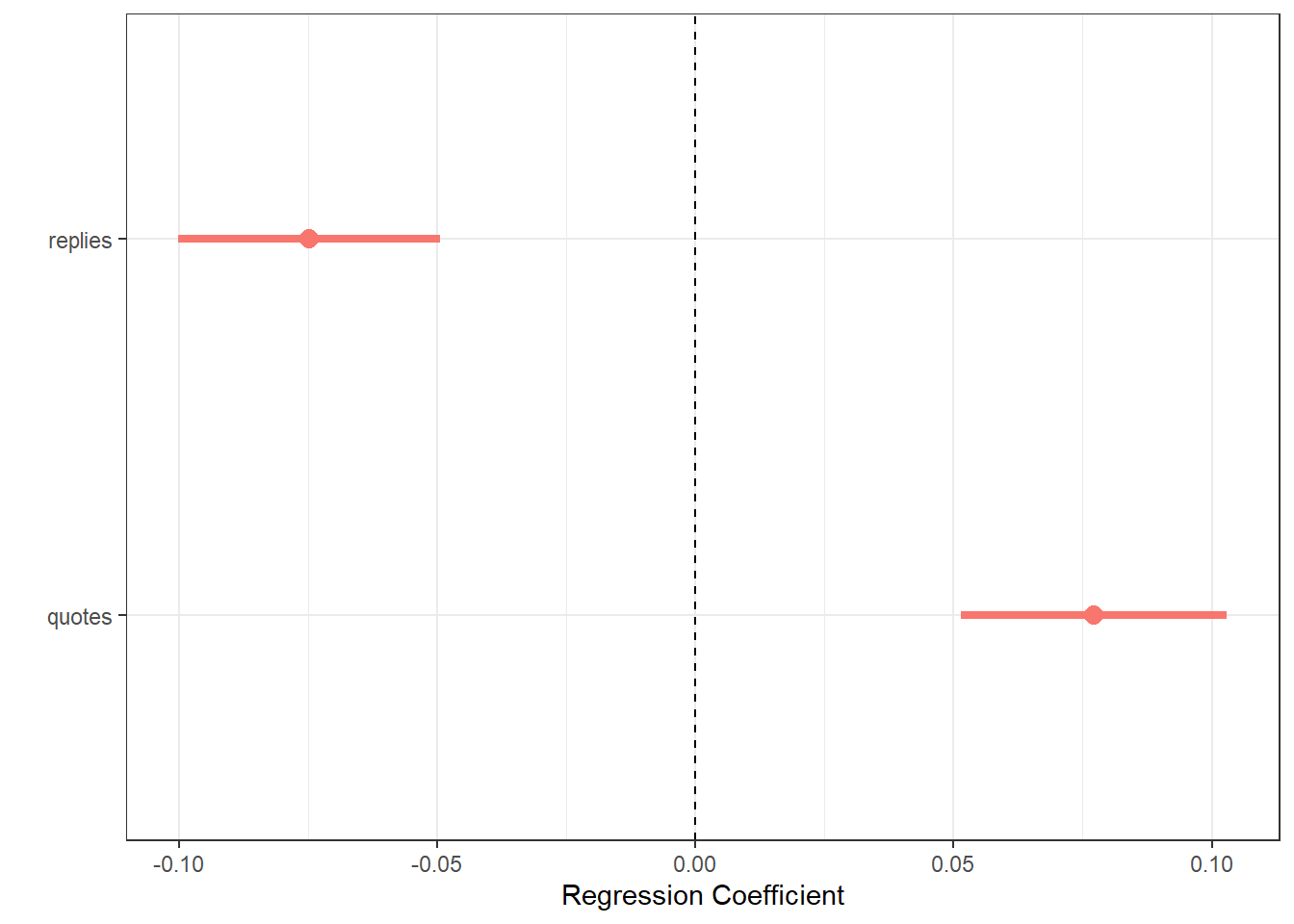
Exercises
On tweets.Rmd, complete the following exercises
69) Sentiments across the time frame
70) Sentiments in different types of tweets
20:00
Analysing Tweets — Concreteness in different types of tweets
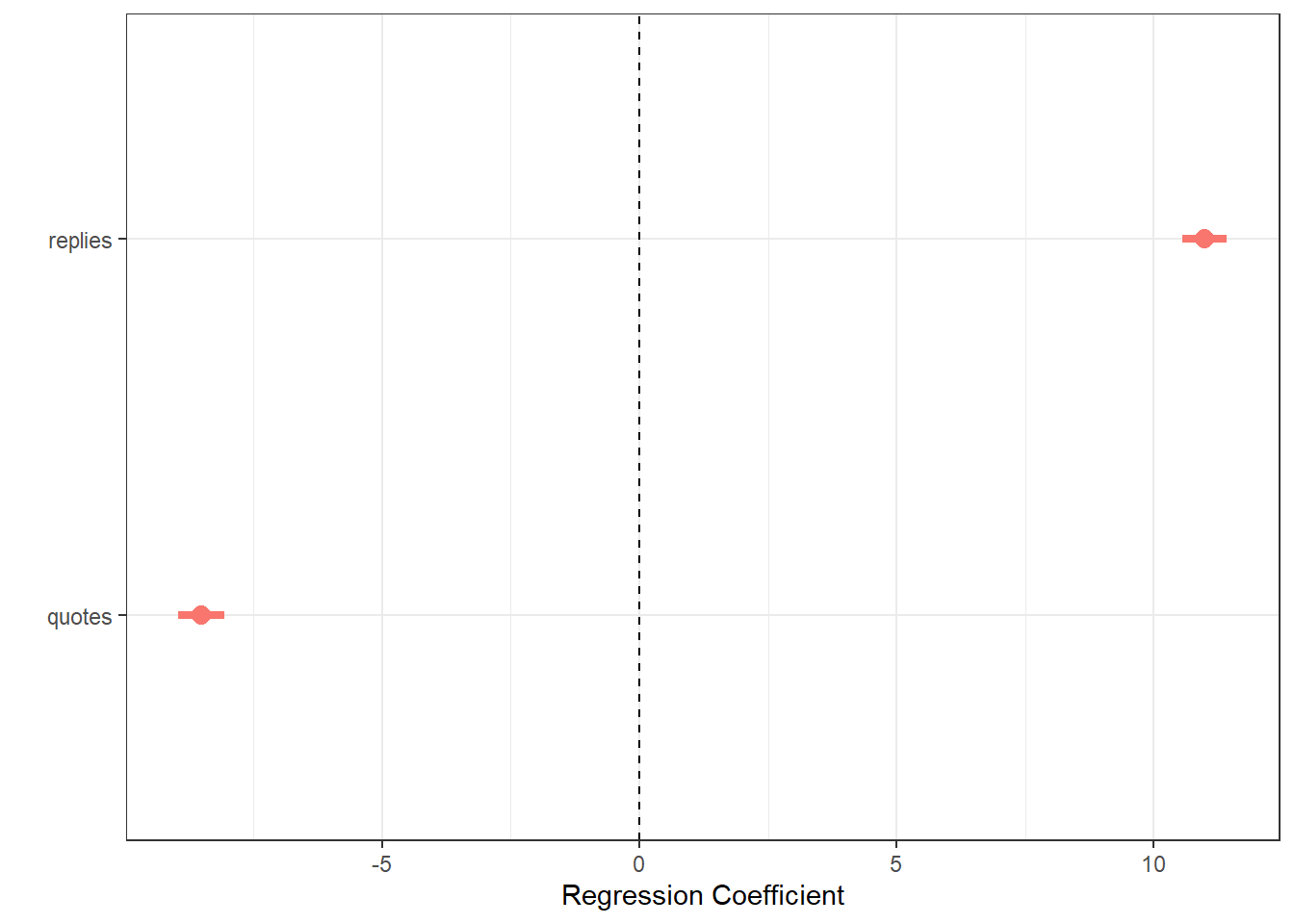
Analysing Tweets — Concreteness by Hours of the Day
Exercises
On tweets.Rmd, complete the following exercises
71) Concreteness in different types of tweets
72) Concreteness by Hours of the Day
73) Something else interesting about MPs
74) Something interesting from your own data
45:00
References
Cheng, J. and W. Chang (2022). httpuv: HTTP and WebSocket Server Library. R package version 1.6.5. https://github.com/rstudio/httpuv.
Jungherr, A. (2016). "Twitter use in election campaigns: A systematic literature review". In: Journal of Information Technology & Politics 13.1, pp. 72-91.
Jürgens, P. and A. Jungherr (2016). "A tutorial for using Twitter data in the social sciences: Data collection, preparation, and analysis". In: Available at http://dx.doi.org/10.2139/ssrn.2710146.
Kearney, M. W. (2020). rtweet: Collecting Twitter Data. R package version 0.7.0. https://CRAN.R-project.org/package=rtweet.
Mellon, J. and C. Prosser (2017). "Twitter and Facebook are not representative of the general population: Political attitudes and demographics of British social media users". In: Research & Politics 4.3, pp. 1-9.
Robinson, D. and J. Silge (2021). tidytext: Text Mining using dplyr, ggplot2, and Other Tidy Tools. R package version 0.3.2. https://github.com/juliasilge/tidytext.
Silge, J. and D. Robinson (2017). Text mining with R: A tidy approach. O'Reilly.
Silva, B. C. and S. Proksch (2021). "Fake It 'Til You Make It: A Natural Experiment to Identify European Politicians' Benefit from Twitter Bots". In: American Political Science Review 115.1, pp. 316-322.
References
Sinnenberg, L., A. M. Buttenheim, K. Padrez, et al. (2017). "Twitter as a tool for health research: a systematic review". In: American Journal of Public Health 107.1, pp. 1-8.
Umit, R. (2017). "Strategic communication of EU affairs: an analysis of legislative behaviour on Twitter". In: The Journal of Legislative Studies 23.1, pp. 93-124.
Wickham, H. (2019). stringr: Simple, Consistent Wrappers for Common String Operations. R package version 1.4.0. https://CRAN.R-project.org/package=stringr.
Wickham, H. (2021). tidyverse: Easily Install and Load the Tidyverse. R package version 1.3.1. https://CRAN.R-project.org/package=tidyverse.
Wickham, H., R. François, L. Henry, et al. (2022). dplyr: A Grammar of Data Manipulation. R package version 1.0.8. https://CRAN.R-project.org/package=dplyr.
Wickham, H. and G. Grolemund (2021). R for data science. O'Reilly.
Xie, Y. (2022). xaringan: Presentation Ninja. R package version 0.23. https://github.com/yihui/xaringan.